

TL;DR Our CI was flaky, our tests hit live APIs, and every run burned tokens unnecessarily. So the CopilotKit team built AIMock - a mock server that covers your entire agentic stack so your tests are fast, free, and actually reliable. Let's dive in!
Why we built AIMock
It started with LLM mocking. We built LLMock, open-sourced it, and thought we were done.
But a single agent request in 2026 can touch six or seven services before it returns a response: the LLM, an MCP tool server, a vector database, a reranker, a web search API, a moderation layer, and a sub-agent over A2A.
Most teams mock one of them. The other six are live, non-deterministic, and quietly making your test suite a lie. That is why LLMock became AIMock.
npm install @copilotkit/aimock
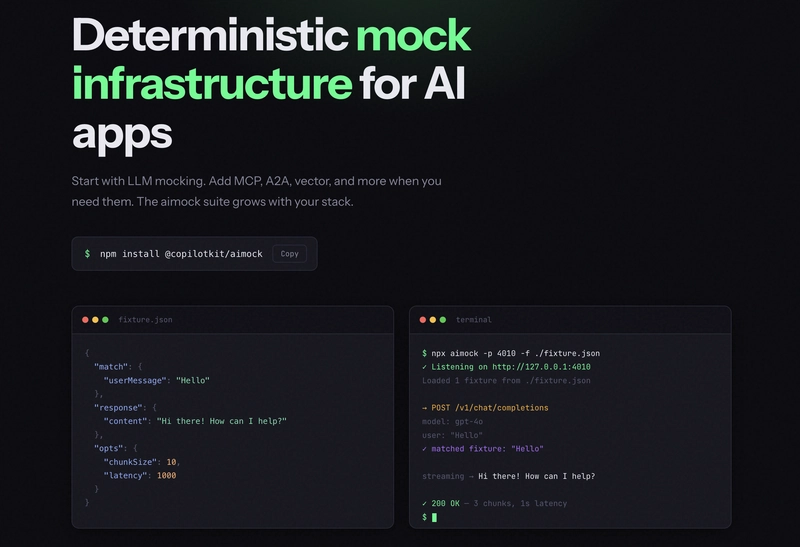
Table of Contents
- AI apps in 2026 call a lot more than just an LLM
- Introducing AIMock: mock your entire agentic stack
- LLMock: full streaming, tool calls, reasoning across every major provider
- MCPMock: a mock MCP server for testing tool integrations
- A2AMock: test multi-agent workflows without live agents
- VectorMock: deterministic retrieval for RAG pipelines
- Services: search, rerank, and moderation
- Drift Detection: catch provider changes before your users do
- Record and Replay: stop hand-writing fixtures
- Chaos Testing: prove your app handles failure
- What else is included
- AG-UI uses AIMock in production
- Migrating to AIMock
AIMock is open source and free.
AI apps in 2026 call a lot more than just an LLM
A realistic agent request looks like this:
User message
→ LLM decides to use a tool
→ Tool call via MCP (file system, database, calendar)
→ RAG retrieval from Pinecone or Qdrant
→ Web search via Tavily
→ Cohere reranker to sort results
→ Back to LLM with full context
Each of these is a live network call in your test environment. Everyone can fail, return something slightly different, or cost you tokens.
We looked at every tool out there. Some handled LLM mocking. Some handled one protocol. None covered the full picture. You would have to stitch together three or four libraries, each with its own config format, and still have gaps.
Here is how AIMock compares to other options out there.


Introducing AIMock: mock your entire agentic stack
It mocks everything your AI app talks to. Here is what is inside:
- LLMock : 11 providers, full streaming, tool calls, reasoning models
- MCPMock : local MCP server with full JSON-RPC 2.0, session management, tools, resources, prompts
- A2AMock : agent card discovery, message routing, SSE streaming between agents
- VectorMock : mock vector database for deterministic RAG retrieval
- Services : search, rerank, and moderation. The APIs everyone forgets to mock.

On top of that, AIMock does three things no other mocking tool does:
Drift Detection : runs daily against real provider APIs and catches response format changes within 24 hours, before your users do
Record and Replay : proxies real API calls, saves them as fixtures, replays them forever in CI without touching live APIs again
Chaos Testing : inject 500s, malformed JSON, and mid-stream disconnects to prove your app handles failure
Run all of them on one port with a single config file:
{
"llm": { "fixtures": "./fixtures/llm", "providers": ["openai", "claude", "gemini"] },
"mcp": { "tools": "./fixtures/mcp/tools.json" },
"a2a": { "agents": "./fixtures/a2a/agents.json" },
"vector": { "path": "/vector", "collections": [] }
}
Get started with the AIMock CLI:
npx aimock --config aimock.json --port 4010
Let's go through each one in brief.
LLMock: full streaming, tool calls, reasoning across every major provider
LLMock runs a real HTTP server on a real port, not in-process patching. Any process on the machine can reach it: your Next.js app, agent workers, LangGraph processes, anything that speaks HTTP.
It has native support for 10 providers: OpenAI, Claude, Gemini, Bedrock, Azure, Vertex AI, Ollama, Cohere, OpenRouter, and Anthropic Azure. Reasoning models are supported across all of them.
Any OpenAI-compatible endpoint, such as Mistral, Groq, Together AI, or vLLM, works out of the box, too. Full streaming, tool calls, structured outputs, extended thinking, multi-turn conversations, and WebSocket APIs are all built in.
AIMock handles the translation internally, so one fixture format works across all providers.
Using the programmatic API with vitest, register a fixture and assert on the response. beforeAll starts the mock server once for the suite, afterAll tears it down, and mock.on() registers a fixture that maps a user message to a deterministic response.
import { LLMock } from "@copilotkit/aimock";
import { describe, it, expect, beforeAll, afterAll } from "vitest";
let mock: LLMock;
beforeAll(async () => {
mock = new LLMock();
await mock.start();
});
afterAll(async () => {
await mock.stop();
});
it("non-streaming text response", async () => {
mock.on({ userMessage: "hello" }, { content: "Hello! How can I help?" });
const res = await fetch(`${mock.url}/v1/chat/completions`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({
model: "gpt-4",
messages: [{ role: "user", content: "hello" }],
stream: false,
}),
});
const body = await res.json();
expect(body.choices[0].message.content).toBe("Hello! How can I help?");
expect(body.object).toBe("chat.completion");
expect(body.id).toMatch(/^chatcmpl-/);
});
Point your existing OpenAI client at the mock URL. Nothing else in your code changes. No API keys, no network calls, the same response every time. Full provider docs here.

MCPMock: a mock MCP server for testing tool integrations
MCP is how agents call tools. If your agent uses MCP, every tool call in your test suite hits a live server with real latency and no control over the response.
MCPMock gives you a local server that speaks the full MCP protocol over JSON-RPC 2.0. Your agent connects to it exactly like a real MCP server. You control what comes back.
import { MCPMock } from "@copilotkit/aimock/mcp";
const mcp = new MCPMock();
mcp.addTool({
name: "search",
description: "Search the web",
inputSchema: { type: "object", properties: { query: { type: "string" } } },
});
mcp.onToolCall("search", (args) => {
const { query } = args as { query: string };
return `Found 3 results for "${query}"`;
});
const url = await mcp.start();
// point your MCP client at `url`
In a real agent test, your LLM and MCP tool server run together. Mount MCPMock onto LLMock so they share one port:
import { LLMock, MCPMock } from "@copilotkit/aimock";
const llm = new LLMock({ port: 5555 });
const mcp = new MCPMock();
mcp.addTool({ name: "calc", description: "Calculator" });
mcp.onToolCall("calc", (args) => "42");
llm.mount("/mcp", mcp);
await llm.start();
// MCP available at http://127.0.0.1:5555/mcp
It supports:
- Tools - register handlers that return strings or rich content
- Resources - static files and data your agent can read via URI
- Prompts - reusable prompt templates with arguments
- Session management - full
Mcp-Session-Idlifecycle per the Streamable HTTP spec
Full docs here.

A2AMock: test multi-agent workflows without live agents
A2A (Agent2Agent) is how agents discover and talk to each other. It handles agent cards, message routing, and streaming responses between agents.
Testing a multi-agent system is hard when every agent is live. One agent goes down, your whole test suite breaks.
A2AMock gives you a local A2A server with full agent card discovery, message routing, task management, and SSE streaming. Register your agents, define how they respond, and test your multi-agent workflows end-to-end without anything actually running.
import { A2AMock } from "@copilotkit/aimock/a2a";
const a2a = new A2AMock();
a2a.registerAgent({
name: "translator",
description: "Translates text between languages",
skills: [{ id: "translate", name: "Translate" }],
});
a2a.onMessage("translator", "translate", [{ text: "Translated text" }]);
const url = await a2a.start();
// Agent card at: ${url}/.well-known/agent-card.json
// JSON-RPC at: ${url}/
Here is the pattern for long-running tasks with incremental updates:
a2a.onStreamingTask("agent", "long-task", [
{ type: "status", state: "TASK_STATE_WORKING" },
{ type: "artifact", parts: [{ text: "partial result" }], name: "output" },
{ type: "artifact", parts: [{ text: "final result" }], lastChunk: true, name: "output" },
], 50); // 50ms delay between events
For task management, agent cards, and JSON-RPC methods, see the full docs here.
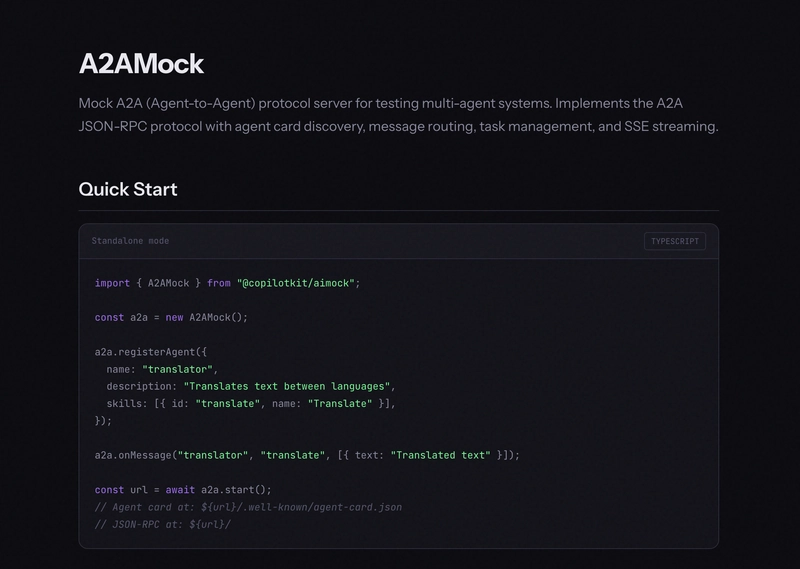
VectorMock: deterministic retrieval for RAG pipelines
If your app does retrieval-augmented generation, your tests depend on what is in your vector database right now. Your dev index is messy, your staging index does not match prod, and results shift every time someone upserts new vectors.
VectorMock is a mock vector database server that supports Pinecone, Qdrant, and ChromaDB API formats with collection management, upsert, query, and delete operations.
import { VectorMock } from "@copilotkit/aimock/vector";
const vector = new VectorMock();
vector.addCollection("docs", { dimension: 1536 });
vector.onQuery("docs", [
{ id: "doc-1", score: 0.95, metadata: { title: "Getting Started" } },
{ id: "doc-2", score: 0.87, metadata: { title: "API Reference" } },
]);
const url = await vector.start();
// point your vector DB client at `url`
If you need results to vary based on the query, use a dynamic handler instead:
vector.onQuery("docs", (query) => {
const topK = query.topK ?? 10;
return Array.from({ length: topK }, (_, i) => ({
id: `result-${i}`,
score: 1 - i * 0.1,
}));
});
Here are compatible endpoints for Pinecone, Qdrant, and ChromaDB APIs.

Consistent retrieval results. Every test run. Full docs here.
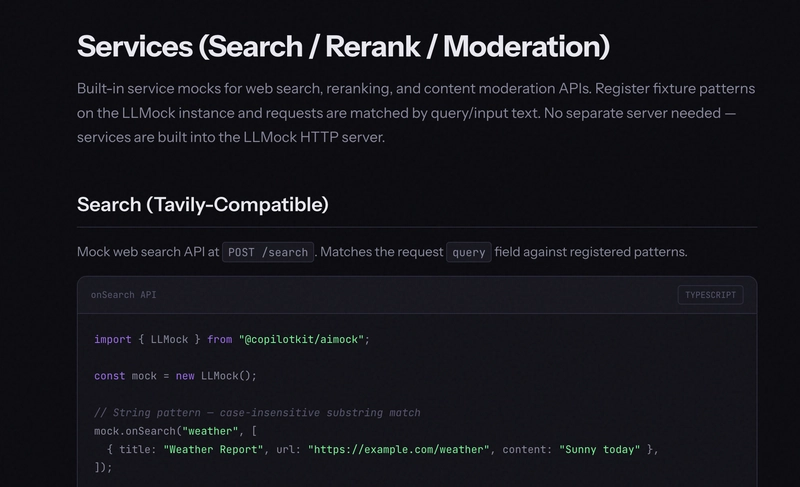
Services: search, rerank, and moderation
These are the APIs most people forget to mock, and the ones that quietly make your test suite non-deterministic.
Services within AIMock provides built-in mocks for web search, reranking, and content moderation. Register fixture patterns on your LLMock instance and requests are matched by query/input text. No separate server needed.
-
Tavily search - mock web search results by query pattern at
POST /search -
Cohere reranking - mock reranked document lists at
POST /v2/rerank -
OpenAI moderation - mock moderation decisions at
POST /v1/moderations. Unmatched requests return unflagged by default.
import { LLMock } from "@copilotkit/aimock";
const mock = new LLMock();
// String pattern — case-insensitive substring match
mock.onSearch("weather", [
{ title: "Weather Report", url: "https://example.com/weather", content: "Sunny today" },
]);
// RegExp pattern
mock.onSearch(/stock\s+price/i, [
{ title: "ACME Stock", url: "https://example.com/stocks", content: "$42.00", score: 0.95 },
]);
// Catch-all — empty results for unmatched queries
mock.onSearch(/.*/, []);
mock.onRerank("machine learning", [
{ index: 0, relevance_score: 0.99 },
{ index: 2, relevance_score: 0.85 },
]);
mock.onModerate("violent", {
flagged: true,
categories: { violence: true, hate: false },
category_scores: { violence: 0.95, hate: 0.01 },
});
If you just need catch-all responses to stop live requests, enable all three in config:
{
"services": {
"search": true,
"rerank": true,
"moderate": true
}
}
String patterns use case-insensitive substring matching. RegExp patterns do full regex testing. First match wins. All service requests are recorded in the journal, so you can inspect exactly what got called. Full docs here.
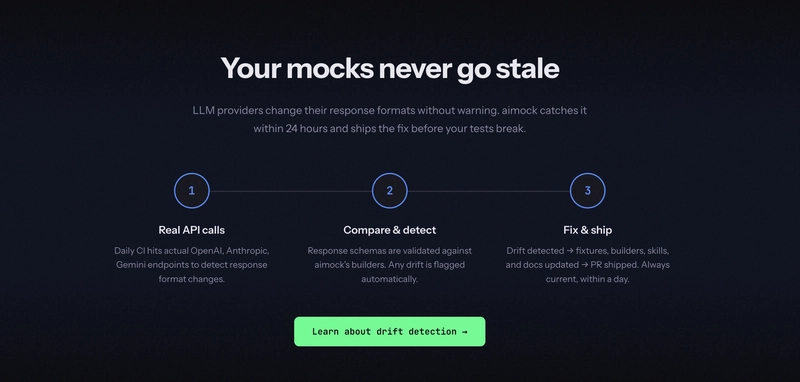
Drift Detection: catch provider changes before your users do
This is one of the things no other mocking tool does. A mock that does not match reality is worse than no mock.
Here is the problem: mocks are a snapshot of how an API behaved when you wrote the fixture. OpenAI adds a field. Claude changes a default. Gemini tweaks its streaming format. Your mocks still pass. CI is green. Then your app breaks in production.
Drift Detection runs a three-way comparison in CI every day:
- SDK types - what TypeScript type definitions say the shape should be
- Real API responses - actual live requests to OpenAI, Anthropic, Gemini
- AIMock output - what the mock returns for the same request
If any of those three disagree, you know within 24 hours. Not when a user files a bug.

Here is what the output looks like when drift is detected:
$ pnpm test:drift
[critical] AIMOCK DRIFT — field in SDK + real API but missing from mock
Path: choices[].message.refusal
SDK: null Real: null Mock: <absent>
[critical] TYPE MISMATCH — real API and mock disagree on type
Path: content[].input
SDK: object Real: object Mock: string
[warning] PROVIDER ADDED FIELD — in real API but not in SDK or mock
Path: choices[].message.annotations
SDK: <absent> Real: array Mock: <absent>
✓ 2 critical (test fails) · 1 warning (logged) · detected before any user reported it
Severity levels:
- Critical : mock mismatches the real API, test fails immediately
- Warning : provider added a new field that neither the SDK nor the mock knows about yet, logged as early warning
- Ok : all three sources agree, nothing to do
Here is how the three-way comparison works under the hood:
import { extractShape, triangulate, formatDriftReport, shouldFail } from "./schema";
// 1. Get the SDK shape (what TypeScript says)
const sdkShape = openaiChatCompletionShape();
// 2. Call the real API and the mock in parallel
const [realRes, mockRes] = await Promise.all([
openaiChatNonStreaming(config, [{ role: "user", content: "Say hello" }]),
httpPost(`${instance.url}/v1/chat/completions`, { /* ... */ }),
]);
// 3. Extract response shapes
const realShape = extractShape(realRes.body);
const mockShape = extractShape(JSON.parse(mockRes.body));
// 4. Three-way comparison
const diffs = triangulate(sdkShape, realShape, mockShape);
const report = formatDriftReport("OpenAI Chat (non-streaming text)", diffs);
// 5. Critical diffs fail the test
if (shouldFail(diffs)) {
expect.soft([], report).toEqual(
diffs.filter(d => d.severity === "critical")
);
}
Run it yourself against live endpoints:
# Run drift checks against live endpoints
pnpm vitest --config vitest.config.drift.ts
MSW, VidaiMock, Mokksy - none of them do this. Your mocks should never silently go stale. Full docs here.
Record and Replay: stop hand-writing fixtures
Writing fixtures by hand is fine for simple cases. It gets painful fast when you are dealing with multi-turn agent conversations with tool calls, streaming responses, and branching logic. MSW, VidaiMock, mock-llm, piyook - none of the LLM mocking tools solve this.
Record and Replay works like a VCR. Here is exactly what happens:
- Client sends a request to AIMock
- AIMock attempts fixture matching as usual
- On miss: the request is forwarded to the configured upstream provider
- The upstream response is relayed back to the client immediately
- The response is collapsed if streaming and saved as a fixture to disk and memory
- Subsequent identical requests match the newly recorded fixture

Quick start using CLI:
$ npx aimock --fixtures ./fixtures \
--record \
--provider-openai https://api.openai.com \
--provider-anthropic https://api.anthropic.com
Recorded fixtures are saved automatically and look like this:
{
"fixtures": [
{
"match": { "userMessage": "What is the weather?" },
"response": { "content": "I don't have real-time weather data..." }
}
]
}
AIMock handles stream collapsing automatically across six formats: OpenAI SSE, Anthropic SSE, Gemini SSE, Cohere SSE, Ollama NDJSON, and Bedrock EventStream. Auth headers are forwarded to the upstream provider but never saved in fixtures.
It also supports a programmatic API with enableRecording() and requestTransform for normalizing dynamic data like timestamps.
In CI, add --strict so that any unmatched request returns a 503 and fails immediately, rather than slipping through silently. Without it, missing fixtures return 404 responses, and your test suite may never tell you that a live API call was attempted.
Full docs here.
Chaos Testing: prove your app handles failure
Your app will eventually get a 500 from OpenAI. A malformed JSON response from a tool. A mid-stream disconnect from a vector database. The question is whether you find out in testing or in production.
Chaos Testing lets you inject failures at configurable probabilities at three levels: server-wide, per fixture, or per individual request.
Three failure modes:
-
drop - returns HTTP 500 with
{"error":{"message":"Chaos: request dropped","code":"chaos_drop"}} - malformed - returns HTTP 200 with invalid JSON
- disconnect - destroys the TCP connection immediately with no response
Server-level chaos applies to all requests:
import { LLMock } from "@copilotkit/aimock";
const mock = new LLMock();
mock.setChaos({
dropRate: 0.1, // 10% of requests return 500
malformedRate: 0.05, // 5% return broken JSON
disconnectRate: 0.02, // 2% drop the connection
});
// remove all chaos later
mock.clearChaos();
Fixture-level chaos targets specific responses only:
{
"fixtures": [
{
"match": { "userMessage": "unstable" },
"response": { "content": "This might fail!" },
"chaos": {
"dropRate": 0.3,
"malformedRate": 0.2,
"disconnectRate": 0.1
}
}
]
}
Per-request headers override everything else - useful for forcing a specific failure in a single test:
// Force 100% disconnect on this specific request
await fetch(`${mock.url}/v1/chat/completions`, {
method: "POST",
headers: {
"Content-Type": "application/json",
"x-aimock-chaos-disconnect": "1.0",
},
body: JSON.stringify({ model: "gpt-4", messages: [{ role: "user", content: "hello" }] }),
});
All chaos events are tracked in the journal with a chaosAction field and counted in Prometheus metrics. Full docs here.
What else is included
Beyond the core modules, AIMock offers a lot more worth knowing.
Embeddings - POST /v1/embeddings is fully supported. Return explicit vectors via fixtures or let AIMock generate them deterministically from a hash of the input text. Same input always produces the same vector, default dimensions are 1536.
WebSocket APIs - OpenAI Realtime, OpenAI Responses over WebSocket, and Gemini Live are all supported using raw RFC 6455 framing. If your app uses voice or real-time streaming agents, these are covered.
Sequential Responses - return different responses for the same prompt on each successive call. Useful for testing retry logic and multi-turn workflows where the same message should behave differently over time.
[
{ "match": { "userMessage": "retry", "sequenceIndex": 0 }, "response": { "content": "First attempt" } },
{ "match": { "userMessage": "retry", "sequenceIndex": 1 }, "response": { "content": "Second attempt" } },
{ "match": { "userMessage": "retry" }, "response": { "content": "Fallback" } }
]
Streaming Physics - configure ttft (time to first token), tps (tokens per second), and jitter to simulate realistic timing. Pre-built profiles cover fast models, reasoning models, and overloaded systems.
Prometheus Metrics - request counts, latency histograms, and current fixture count at /metrics. Enable with --metrics flag.
Docker and Helm - the official Docker image is available at ghcr.io/copilotkit/aimock (GitHub Container Registry) for CI/CD. It runs as a plain HTTP server, so any language can use it. No Node.js needed on the test runner side.
AG-UI uses AIMock in production
AG-UI is the open protocol that connects AI agents to frontend applications - adopted by LangGraph, CrewAI, Mastra, Google ADK, AWS Bedrock AgentCore, and more.

It uses AIMock for its end-to-end test suite, verifying AI agent behavior across LLM providers with fixture-driven responses. AG-UI is a protocol used in production. If you want to see what a real AIMock setup looks like at scale, that is a good place to start.
Migrating to AIMock
The docs include step-by-step migration guides for MSW, VidaiMock, mock-llm, Python mocks and Mokksy. You will find a side-by-side comparison and a breakdown of what you gain and keep.
If you are on MSW, you do not have to replace everything: you can keep MSW for general REST and GraphQL mocking and use AIMock only for AI endpoints.
If you are already using @copilotkit/llmock, the upgrade is a find-and-replace:
pnpm remove @copilotkit/llmock
pnpm add @copilotkit/aimock
The LLMock class, all fixture formats, and the programmatic API are unchanged. Your existing tests will work as-is.
Get started
npm install @copilotkit/aimock
- Docs: aimock.copilotkit.dev
- GitHub: github.com/CopilotKit/aimock
- npm: @copilotkit/aimock
- CLI: AIMock CLI
Your test suite should be as complete as your stack. That is what AIMock is for.
You can connect me on GitHub, Twitter and LinkedIn.
Follow CopilotKit on Twitter and say hi, and if you'd like to build something cool, join the Discord community.



Top comments (29)
Great concept—this is exactly the kind of tooling AI teams need as stacks get more complex.
Love how AIMock goes beyond just LLM mocking and actually covers the entire agentic pipeline (LLM + MCP + vector DB + search + rerank, etc.). That’s a huge gap in current testing setups where people mock one layer and unknowingly leave the rest non-deterministic.
The record & replay + drift detection combo is especially powerful—feels like a practical way to keep tests realistic without silently breaking when providers change APIs.
Curious how it performs at scale in large CI pipelines and whether teams mix it with tools like MSW or fully replace their existing mocks?
thanks! on the MSW question -- you don't have to fully replace it. the recommendation is to keep MSW for general REST/GraphQL mocking and aimock for AI-specific endpoints. the docs have a section specifically on using them alongside each other.
aimock.copilotkit.dev/migrate-from...
as for CI scale, it runs as a plain HTTP server so any process can hit it and the Docker image makes it straightforward to drop into pipelines.
aimock.copilotkit.dev/aimock-cli/
Hello handsome, how are you doing ?
Excellent article on AIMock! Love how it mocks the entire agentic stack—from LLMock with 11+ providers to MCPMock, A2AMock, VectorMock, and even overlooked services like search/rerank. The drift detection, record & replay, and chaos testing are game-changers for reliable, fast CI without token burn or flakiness. Open-source gold for 2026 AI devs—huge thanks to the CopilotKit team! 🚀
Drift detection is the killer feature here. Most AI mock servers just replay canned responses, but the real pain point is when prompts evolve and tests still pass against stale fixtures. Having the mock flag when real API behavior has drifted prevents an entire class of bugs that only surface in production. Would love to see cost tracking in mock mode too — estimating token usage during tests could catch expensive prompt patterns before they hit real APIs.
yep, the ability to run daily drift detection to catch provider changes is super practical :)
cost tracking is an interesting idea but feels like a separate use case. feel free to create a discussion in the repo if you are using aimock & really want this.
The testing problem you're solving is real — flaky CI caused by live API calls is one of the most underestimated sources of wasted engineering time. AIMock's approach of covering the full agentic stack (MCP, A2A, vector, moderation) in one fixture layer is exactly the kind of abstraction the ecosystem needs.
One layer that becomes critical once you move past local testing is governance at the MCP server level in production. When your agents are calling real GitHub, Slack, or database MCP servers autonomously, questions emerge fast: who called what, when, and can you prove it? How do you prevent sensitive payloads from reaching the LLM? Can you kill a misbehaving agent instantly?
Vinkius (vinkius.com) addresses this by running 2,000+ pre-governed MCP servers inside V8 Isolate sandboxes — each with SHA-256 cryptographic audit trails, compiled PII redaction, and a global kill switch. The SDK is Vurb.ts, which wraps MCP tool calls with governance primitives baked in rather than bolted on.
AIMock solves the dev/test phase; Vinkius solves the production governance phase. Used together, you'd have a complete lifecycle: deterministic tests locally, auditable execution in production. Solid work from the CopilotKit team — the drift detection feature alone would save a lot of on-call headaches.
The drift detection is the standout feature here. I've gone through 12 agent codebases and the number of times I've seen tests pass against mocks that no longer match the real API is depressing. Most teams find out when a user reports it, not when CI catches it.
The chaos testing part maps to real problems too. Most agents I've analyzed have zero error handling for mid-stream disconnects -- they just crash or silently drop the partial response. Being able to inject that in tests before it happens in prod is worth the whole tool.
yep, drift detection, record & replay, chaos testing are the most useful things here that no mocking tool has... and it's all open source so if you want to contribute or extend it, go for it. hope the community loves this, deserves all the attention :)
we were spending like $40/day just on test runs hitting live endpoints. switched to recording responses and replaying them which helped but maintaining those fixtures became its own nightmare. curious how this handles streaming responses and partial chunks since that's where most mock setups fall apart for us.
Really well written and whoever worked on the docs deserves credit, the drift detection page is very clear on why the problem exists, not just how to use the tool.
One question on A2AMock- when you register agents with onMessage, are handlers stateless per request or is there a way to carry context across a chain so agent B can reference what agent A returned in the same task flow?
docs are really nice. as far as I'm aware handlers are stateless per request right now so agent B can't natively reference what agent A returned in the same flow. pls create an issue in the repo and I'm sure the team will look into it!
Drift detection is the killer feature that makes this more than just another mocking library. The fundamental problem with AI mocks is that they rot silently — the provider changes a response shape, your mock still returns the old format, CI stays green, and you discover the mismatch in production. The three-way comparison (SDK types vs real API vs mock output) is the right architecture for catching that. The chaos testing for mid-stream disconnects is also addressing a real gap. I've seen so many agent implementations that handle clean errors fine but completely fall apart on partial streaming responses where the TCP connection drops after 3 chunks. That failure mode is nearly impossible to reproduce manually but trivial with configurable disconnect rates. The fact that this covers MCP, A2A, and vector DBs alongside LLMs in one server is what makes it practical — stitching together separate mock tools per protocol is exactly the kind of yak-shaving that kills test coverage.
AIMock looks like a practical solution for streamlining AI development—having one mock server for the entire stack can simplify testing, reduce dependencies, and speed up iteration. It’s especially useful for teams working with multiple AI services and APIs.
The drift detection feature is something I wish existed when I was building my test framework. I ended up with a different problem in the same space — not mocking AI responses, but validating that data stays consistent across layers (UI → API → DB). I used set theory on the DB state to mathematically prove that exactly one record changed per operation.
Your point about "the other six services are live and quietly making your test suite a lie" really resonates. In my case it was simpler — just three layers — but the same principle applies: if you're only mocking one thing, you're testing your mocks, not your system.
Curious about one thing: does AIMock support asserting on the sequence of calls across services? Like verifying that the LLM was called before the vector DB, not after?
as far as I'm aware there's no dedicated way to assert call sequence across services right now. the journal does log all calls across LLM, A2A, vector etc. so you could read it after the test and check ordering yourself but that's more of a workaround. pls create a feature request in the repo!
Some comments may only be visible to logged-in visitors. Sign in to view all comments.