
Final part of the Epistemic AI series. We've covered the problem, measurement, calibration, and integration. Now: how AI learns to sound like you — and why that matters more than you think.
When you write a Reddit comment, a Dev.to article, and a LinkedIn post about the same topic, you change how you write. Not the facts — the voice. The register shifts. The depth adjusts. The cultural expectations of each platform shape what "good" looks like.
Your AI doesn't know this. It writes the same way everywhere — the same helpful, slightly formal, universally inoffensive tone that's instantly recognizable as machine-generated. That's not a style problem. It's a measurement problem.
The Voice Gap
Every AI writing tool faces the same structural limitation: the model has no memory of how you write, where you're writing, or what has actually worked for your audience before.
This creates three predictable failures:
The identity gap. The AI doesn't know your natural register — whether you lead with data or analogy, whether you hedge or state directly, whether you use jargon or translate. It defaults to "helpful assistant" because it has no evidence to do otherwise.
The platform gap. Reddit has anti-marketing antibodies. Dev.to rewards show-don't-tell technical narrative. LinkedIn expects professional polish. The AI doesn't adapt to these cultural norms because it doesn't track them. It writes the same way on every platform, and it underperforms on all of them.
The learning gap. After you publish, some content works and some doesn't. Engagement data exists — reactions, comments, reads, saves. But none of that feeds back into the next generation cycle. The AI starts from the same blank slate every time. It never gets better at being you.
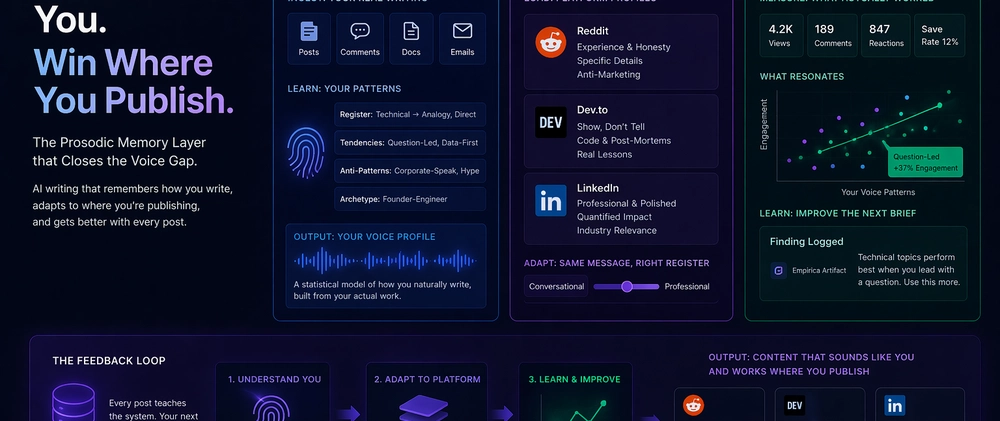
The Tri-Axis Model
We built something to solve this. The prosodic memory layer — built on top of Empirica's epistemic measurement infrastructure — tracks writing patterns across three axes:
Axis 1: Creator Voice
Your writing DNA. Not what you say, but how you say it.
The system ingests your actual writing — posts, comments, documentation, emails — and builds a voice profile from real samples. Not a prompt like "write in a casual tone." A statistical model of your natural tendencies:
- Register: formal, conversational, technical, casual — and how it shifts by context
- Tendencies: "technical-then-analogy," "question-led," "data-first"
- Anti-patterns: "corporate-speak," "hype-language," "over-qualifying"
- Archetype: founder-engineer, researcher, marketer, writer
Each sample is embedded as a semantic vector with metadata — platform, audience, register, engagement score, topic tags. When the system needs to write as you, it doesn't guess from a prompt. It retrieves your closest real writing for that context and uses it as a stylistic reference.
Axis 2: Platform Adaptation
Each platform has cultural norms that override personal style. The system encodes these as structured profiles:
Dev.to rewards code examples readers can run, "how I built X" narratives, and honest post-mortems. Theory without code underperforms. Thinly disguised product announcements get called out.
Reddit rewards personal experience framing, openly acknowledged uncertainty, and specific technical details. Marketing language gets instant downvotes. Self-promotion without value contribution gets buried.
LinkedIn rewards professional framing, quantified results, and industry-relevant insights. The register is professional but authentic — pure corporate-speak reads as hollow.
When the system generates content, it loads the target platform's profile and adapts the voice accordingly. Same message, different register. Your Dev.to article and your Reddit comment on the same topic should sound like they were written by the same person — on purpose, with intent — not like copy-paste.
Axis 3: Audience Reception
The feedback loop. After publishing, engagement data flows back — reactions, comments, reads, saves — normalized into comparable metrics across platforms.
The system detects which patterns resonate with which audiences:
- Which register outperforms on which platform
- Which topics consistently drive engagement
- Which voice patterns (your real ones) correlate with the best reception
These patterns become findings — logged as Empirica artifacts — and feed into the next content generation cycle. The brief gets richer each time. The AI doesn't just know how you write. It knows how you write when things work.
The Content Brief: Three Layers Merged
When the AI generates content, all three axes merge into a single brief — a structured context document that tells the drafter exactly what it's working with:
PLATFORM: Dev.to
- Cultural norms: technical-narrative, show-don't-tell
- What works here: code examples, honest post-mortems
- Min confidence to post: 70%
ENGAGEMENT DATA:
- Platform average: 0.45 (32 published samples)
- Top topics: epistemic-uncertainty (0.81), calibration (0.67)
CREATOR VOICE:
- Archetype: founder-engineer
- Natural register: technical
- Tendencies: technical-then-analogy, data-before-opinion
- Anti-patterns: corporate-speak, hype-language
The drafter sees all three layers. The result reads like the creator wrote it, adapted for the platform, informed by what actually gets engagement. Not because we fine-tuned a model. Because we gave it the right context — measured, structured, evidence-based.
The Loop That Learns
This is where prosodic memory connects back to the epistemic measurement layer from the rest of this series:
1. Ingest writing samples → semantic vectors (voice model)
2. Build creator profile → structured voice DNA
3. Generate content → informed by 3-layer brief
4. Publish to platform
5. Fetch engagement data → normalized metrics
6. Detect patterns → findings logged as Empirica artifacts
7. Next cycle → brief includes engagement patterns
Each cycle, the brief gets richer. The system learns not just how you write, but how you write when it works. That's the difference between voice matching and voice optimization.
And because it's built on Empirica's artifact system, every insight is traceable. You can see which engagement findings influenced which generation cycle. You can audit why the system chose a particular register. The voice layer is measured, not magical.
Why This Matters Beyond Content
The prosodic memory concept extends beyond writing. Any AI interaction where consistency of approach matters — customer support, legal drafting, medical documentation, financial reporting — has the same structural problem: the AI defaults to its training distribution, not to the human's established patterns.
The tri-axis model is generalizable:
- Axis 1 (Creator Voice) → Domain Expert Voice — how this doctor explains diagnoses, how this lawyer drafts contracts
- Axis 2 (Platform Adaptation) → Context Adaptation — patient-facing vs. chart notes, client memo vs. filing
- Axis 3 (Audience Reception) → Outcome Measurement — patient comprehension, legal precision, compliance rates
The infrastructure is the same. Ingest real samples. Build a profile. Adapt to context. Measure outcomes. Feed back.
The Connection to Calibration
Prosodic memory is grounded calibration applied to voice instead of code.
In the coding context (Parts 1-4 of this series), the AI declares what it knows, then deterministic evidence — tests, linters, git metrics — verifies the claim. The gap between self-assessment and evidence is the calibration signal.
In the voice context, the AI generates content in your voice, then engagement data — reactions, reads, comments — verifies whether the voice worked. The gap between expected performance and actual reception is the voice calibration signal. Same framework, different evidence source.
This is what makes it structural rather than cosmetic. We're not prompt-engineering a tone. We're measuring voice accuracy the same way we measure epistemic accuracy — with falsifiable evidence, tracked over time, compounding in value.
This concludes the Epistemic AI series. All five parts:
- Your AI Doesn't Know What It Doesn't Know
- Measuring What Your AI Learned
- Grounded Calibration vs Self-Assessment
- Adding Epistemic Hooks to Your Workflow
- The Prosodic Memory Layer (this article)
Empirica is open source (MIT). GitHub
The prosodic memory layer is part of a commercial product built on Empirica's measurement infrastructure. The concepts described here — tri-axis voice modeling, platform adaptation, engagement feedback loops — represent the direction we're building. If you're interested in early access or collaboration, reach out.


Top comments (1)
Great Article Thnks For this'