
![Cover image for [AutoBe] Qwen 3.5-27B Just Built Complete Backends from Scratch — 100% Compilation, 25x Cheaper](/samchon/autobe-https-media2.dev.to/dynamic/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fj759b63mo2vv5sps1b0d.png)
Qwen 3.5-27B Just Built Complete Backends from Scratch
We ran Qwen 3.5-27B on 4 backend generation tasks — from a todo app to a full ERP system. Every single project compiled. The output was nearly identical to Claude Opus 4.6, at 25x less cost.
This is AutoBe — an open-source system that turns natural language into complete, compilable backend applications.
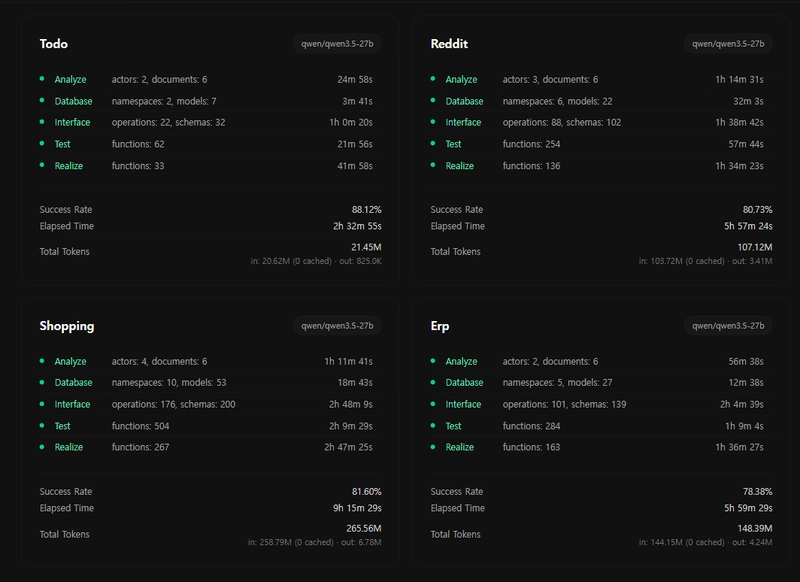
1. Generated Examples
All generated by Qwen 3.5-27B. All compiled. All open source.
From a simple todo app to a full-scale ERP system. Each includes Database schema, OpenAPI spec, API implementation, E2E tests, and type-safe SDK.
2. The Benchmark
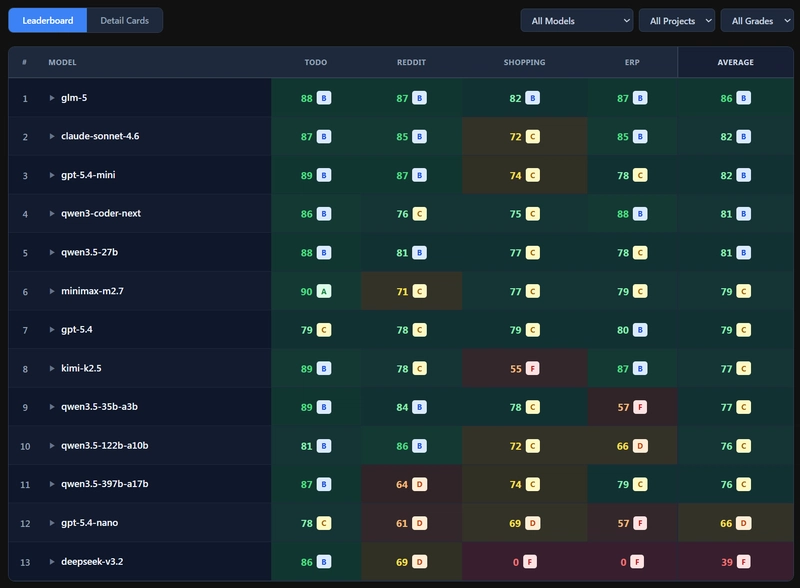
11 models benchmarked. Scores are nearly uniform — from Qwen 3.5-27B to Claude Sonnet 4.6.
A 27B model shouldn't match a frontier model. So why are the outputs identical? Because the compiler decides output quality — not the model.
3. Cost
| Model | Input / 1M tokens | Output / 1M tokens |
|---|---|---|
| Claude Opus 4.6 | $5.000 | $25.000 |
| Qwen 3.5-27B (OpenRouter) | $0.195 | $1.560 |
~25x cheaper on input. ~16x on output. Self-host Qwen and it drops to electricity.
4. How Is This Possible?
AutoBe doesn't generate text code. Instead, LLMs fill the AST structures of AutoBe's custom-built compilers through function calling harness.
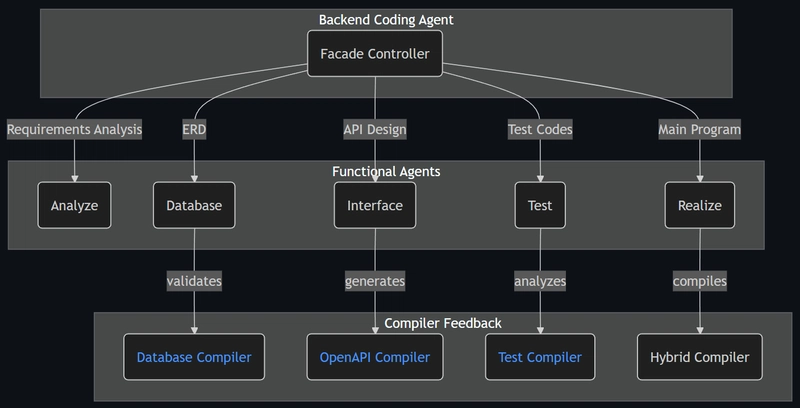
Four compilers validate every output, and when something fails, the compiler's diagnoser feeds back exactly what broke and why. The LLM corrects only the broken parts and resubmits — looping until every compiler passes.
This harness is tight enough that model capability differences don't produce quality differences. They only affect how many retries it takes — Claude Opus gets there in 1-2 attempts, Qwen 3.5-27B in 3-4. Both converge to the same output. That's why the benchmark distribution is so uniform.
"If you can verify, you converge."
5. Coming Soon: Qwen 3.5-35B-A3B
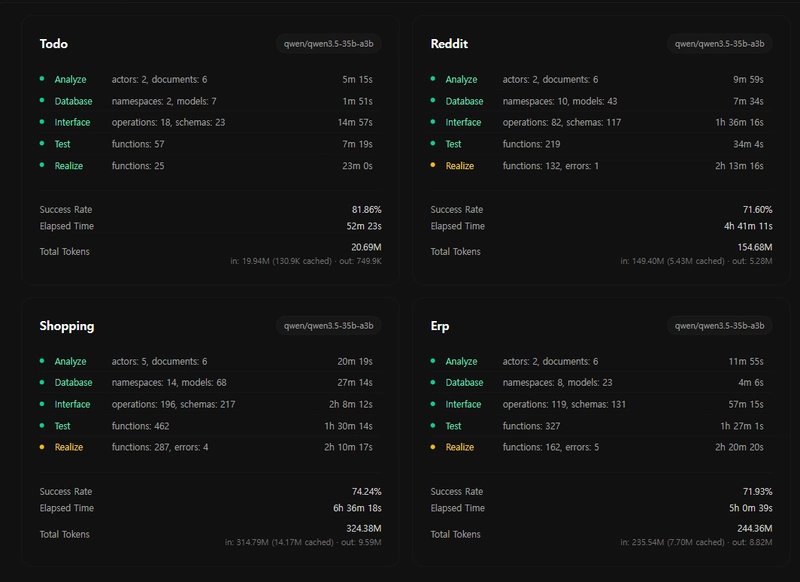
Only 3B active parameters. Not at 100% yet — but close.
When it gets there: 77x cheaper, running on a normal laptop.
No cloud. No high-end GPU. Just your machine building entire backends.
6. Try It
git clone https://github.com/wrtnlabs/autobe
pnpm install
pnpm playground
Star the repo if this is useful: https://github.com/wrtnlabs/autobe


Top comments (6)
Finally, succeeded to achive 100% success rate even in the
qwen3.5-35b-a3bmodel.github.com/wrtnlabs/autobe-example...
Can it run using 2bit quant? unsloth gguf.
I'm getting 120tps on rtx5070 with 12gb vram in llama.cpp. But can only fit 2bit in the memory on that fast speed.
I tested from OpenRouter only. Tell me if it works
Not bad, I am using stepfun3.5flash to build full orchestration frameworks and user interface. Backend frontend everything built in an 8hr autonomous session running on my 4th gen i7 asus hotspotted from my mobile.BY THE POWER OF THE UNIVERSE
I HAVE THE POWER- HE-MAN!
You shou sell API directly with 1/10 price of claude. Do not sell an app.
Not selling app, not selling API, but sharing open source.