Downloaded 18 times






![13
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
LoyaltyInfo
Results
Orders
CUSTOMER
• NoSQL systems provide specialized APIs
• Key-Value get and set
• Each task requires custom built program
• Should test & maintain it](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-13-320.jpg)
![15
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
LoyaltyInfo
ResultDocuments
Orders
CUSTOMER](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-15-320.jpg)


![18
N1QL : Data Types from JSON
Data Type Example
Numbers { "id": 5, "balance":2942.59 }
Strings { "name": "Joe", "city": "Morrisville" }
Boolean { "premium": true, "balance pending": false}
Null { "last_address": Null }
Array { "hobbies": ["tennis", "skiing", "lego"]}
Object { "address": {"street": "1, Main street", "city":
Morrisville, "state":"CA", "zip":"94824"}}
MISSING
Arrays of objects of arrays [
{
"type": "visa",
"cardnum": "5827-2842-2847-3909",
"expiry": "2019-03"
},
{
"type": "master",
"cardnum": "6274-2542-5847-3949",
"expiry": "2018-12"
}
]](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-18-320.jpg)
![19
N1QL: Data Manipulation Statements
•SELECT Statement-
•UPDATE … SET … WHERE …
•DELETE FROM … WHERE …
•INSERT INTO … ( KEY, VALUE ) VALUES …
•INSERT INTO … ( KEY …, VALUE … ) SELECT …
•MERGE INTO … USING … ON …
WHEN [ NOT ] MATCHED THEN …
Note: Couchbase provides per-document atomicity.](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-19-320.jpg)

![22
N1QL: SELECT Statement Highlights
• Querying across relationships
• INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN (5.5)
• Subqueries
• Aggregation (HUGE PERFORMANCE IMPROVEMENT IN 5.5)
• MIN, MAX
• SUM, COUNT, AVG, ARRAY_AGG [ DISTINCT ]
• Combining result sets using set operators
• UNION, UNION ALL, INTERSECT, INTERSECT ALL, EXCEPT, EXCEPT ALL](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-22-320.jpg)
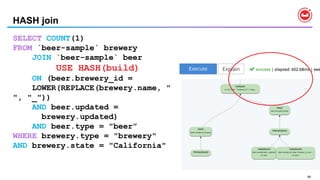
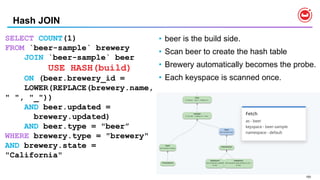
![23
N1QL : Query Operators [ 1 of 2 ]
•USE KEYS …
• Direct primary key lookup bypassing index scans
• Ideal for hash-distributed datastore
• Available in SELECT, UPDATE, DELETE
•JOINs
• INNER, LEFT OUTER, limited RIGHT-OUTER
• Nested loop JOIN is the default
• HASH JOIN for significantly better performance with larger amount of data.
• Ideal for hash-distributed datastore](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-23-320.jpg)
![24
N1QL : Query Operators [ 2 of 2 ]
• UNNEST
• Flattening JOIN that surfaces nested objects as top-level documents
• Ideal for decomposing JSON hierarchies
• Example: Flatten customer document to customer-orders
•NEST
• Does the opposite of UNNEST
• Special JOIN that embeds external child documents under their parent
• Ideal for JSON encapsulation
•JOIN, NEST, and UNNEST can be chained in any combination](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-24-320.jpg)
![25
UNNEST
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
]
}
"c": {
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
]
},
"type" : "master",
"cardnum" : "6274-2842-2847-3909”
}
SELECT c, b.type, b.cardnum
FROM customer c
UNNEST c.Billing AS b
"c": {
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
]
},
"type" : "visa",
"cardnum" : "5827-2842-2847-3909”
}](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-25-320.jpg)
![26
N1QL : Expressions for JSON
Ranging over collections
• WHERE ANY c IN children SATISFIES c.age > 10 END
• WHERE EVERY r IN ratings SATISFIES r > 3 END
Mapping with filtering • ARRAY c.name FOR c IN children WHEN c.age > 10 END
Deep traversal, SET,
and UNSET
• WHERE ANY node WITHIN request SATISFIES node.type = “xyz” END
• UPDATE doc UNSET c.field1 FOR c WITHIN doc END
Dynamic Construction
• SELECT { “a”: expr1, “b”: expr2 } AS obj1, name FROM … // Dynamic
object
• SELECT [ a, b ] FROM … // Dynamic array
Nested traversal • SELECT x.y.z, a[0] FROM a.b.c …
IS [ NOT ] MISSING • WHERE name IS MISSING](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-26-320.jpg)



















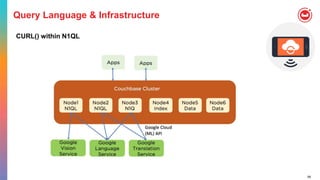
![56
Query Language & Infrastructure
CURL() within N1QL
• CURL (URL, [options])
• The first argument is the URL, which represents any URL that points to a JSON
endpoint.
• Only URLs with the http:// or the https:// protocol are supported.
• Redirection is disabled.
• The second argument is a list of options.
• This is a JSON object that contains a list of curl options and their corresponding
values.
• For a full list of options that we support, please refer to the Dzone article on
CURL in N1QL by Isha Kandaswamy
•](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-56-320.jpg)


![60
Query Optimizer & Execution: Stable Scans
• IndexScan use to do single range scan (i.e single Span)
• If the query has multiple ranges (i.e. OR, IN, NOT clauses) Query service used
to do separate IndexScan for each range.
• This causes Indexer can use different snapshot for each scan (make it unstable scan)
• Number of IndexScans can grow and result increase in index connections
• In 5.0.0 multiple ranges are passed into indexer and indexer uses same
snapshot for all the ranges.
• This makes stable Scan for given IndexScan (i.e. IndexScan2 in the EXPLAIN).
• This will not make stable scan for query due to Subqueries, Joins etc
• Example:
CREATE INDEX ix1 ON default(k0);
EXPLAIN SELECT META().id FROM default WHERE k0 IN [10,12,13];](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-60-320.jpg)



![64
Query Optimizer: Index Projection
• The index can have many keys but query might be interested only
subset of keys.
• By only requesting required information can save lot of network
transportation, memory, cpu, backfill etc. All this can help in
performance and scaling the cluster.
• The requested information can be found in “IndexScan2” Section of
EXPLAIN as “index_projection”
"index_projection": {
"entry_keys": [1, 5 ],
"primary_key": true
}
CREATE INDEX ix1 ON default(k0,k1,k2,k3,k4, k5);
EXPLAIN SELECT meta().id, k1, k5
FROM default
WHERE k0 > 10 AND k1 > 20;](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-64-320.jpg)
![65
Query Optimizer: Index Projection
CREATE INDEX ix1 ON default(k0,k1);
Covered query
SELECT k0 FROM default WHERE k0 = 10 AND k1 = 100;
"index_projection": {"entry_keys": [0,1]}
SELECT k0 FROM default WHERE k0 = 10;
"index_projection": {"entry_keys": [0]}
SELECT k0 ,META().idFROM default WHERE k0 = 10;
"index_projection": {"entry_keys": [0],“primary_key”: true}
Non-covered query
SELECT k0 ,k5 FROM default WHERE k0 = 10 AND k1 = 100;
"Index_projetion": { “primary_key”: true }](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-65-320.jpg)





![72
Solution: Intersection
• Option 3
• Too many keys to manage/specify
• The document is flexible. I want the index to be flexible.
CREATE INDEX ixpairon CUSTOMER(DISTINCT PAIRS(self));
SELECT * FROM CUSTOMER WHERE a = 10 and b < 20 and c between 30 and 40;
"#operator": "IntersectScan",
"scans": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan2",
"index": "ixpair",
"index_id": "466c0c5c4c3b21c1",
"index_projection": {
"primary_key": true
},
"keyspace": "test",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "["a", 10]",
"inclusion": 3,
"low": "["a", 10]"
}
"range": [
{
"high": "["b", 20]",
"inclusion": 1,
"low": "["b", false]"
}
"range": [
{
"high": "[successor("c")]",
"inclusion": 1,
"low": "["c", 30]"
}
]](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-72-320.jpg)
![74
SECURITY : GRANT and REVOKE to roles
• Query_select, query_insert, query_update, query_delete roles
• Parameterized: query_select[customers] or query_insert[*]
• Query_manage_index[foo]
• Create, delete, build indexes on bucket foo
• Query_system_catalog
• Full access to the system tables (which are controlled now)
• Query_external_access
• Allows access to CURL() function (disabled by default)
GRANT cluster_admin TO spock
GRANT query_select ON default TO kirk
REVOKE query_insert, query_delete ON bridge, engineering FROM mccoy, scotty](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-74-320.jpg)

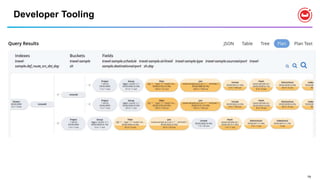







![88
N1QL : Arrays
Array { "hobbies": ["tennis", "skiing", "lego"]}
{ "orders": [582, 9721, 3814]}
Object { "address": {"street": "1, Main street",
"city": Morrisville, "state":"CA",
"zip":"94824"} }
Arrays of objects of arrays [
{
"type": "visa",
"cardnum": "5827-2842-2847-3909",
"expiry": "2019-03"
},
{
"type": "master",
"cardnum": "6274-2542-5847-3949",
"expiry": "2018-12"
}
]](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-88-320.jpg)

![90
Play with ANSI JOIN Support for Arrays - Setup
CREATE PRIMARY INDEX ON product;
"product01", {"productId":
"product01", "category": "Toys",
"name": "Truck", "unitPrice":
9.25}
"product02", {"productId":
"product02", "category":
"Kitchen", "name": "Bowl",
"unitPrice": 5.50}
"product03", {"productId":
"product03", "category":
"utensil", "name": "Spoons",
"unitPrice": 2.40}
CREATE PRIMARY INDEX ON purchase;
"purchase01", {"purchaseId": "purchase01",
"customerId": "customer01", "lineItems": [
{"productId": "product01", "count": 3},
{"productId": "product02", "count": 1} ],
"purchasedAt": "2017-11-24T15:03:22”}
"purchase02", {"purchaseId": "purchase02",
"customerId": "customer02", "lineItems": [
{"productId": "product03", "count": 2} ],
"purchasedAt": "2017-11-27T09:08:37”}](https://image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-90-320.jpg)






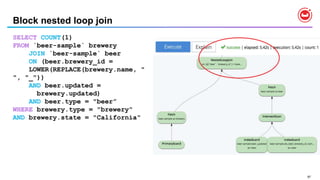












![13
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
LoyaltyInfo
Results
Orders
CUSTOMER
• NoSQL systems provide specialized APIs
• Key-Value get and set
• Each task requires custom built program
• Should test & maintain it](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-13-320.jpg)

![15
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
],
"Connections" : [
{
"CustId" : "XYZ987",
"Name" : "Joe Smith"
},
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
{
"CustId" : "PQR823",
"Name" : "Dylan Smith"
}
],
"Purchases" : [
{ "id":12, item: "mac", "amt": 2823.52 }
{ "id":19, item: "ipad2", "amt": 623.52 }
]
}
LoyaltyInfo
ResultDocuments
Orders
CUSTOMER](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-15-320.jpg)


![18
N1QL : Data Types from JSON
Data Type Example
Numbers { "id": 5, "balance":2942.59 }
Strings { "name": "Joe", "city": "Morrisville" }
Boolean { "premium": true, "balance pending": false}
Null { "last_address": Null }
Array { "hobbies": ["tennis", "skiing", "lego"]}
Object { "address": {"street": "1, Main street", "city":
Morrisville, "state":"CA", "zip":"94824"}}
MISSING
Arrays of objects of arrays [
{
"type": "visa",
"cardnum": "5827-2842-2847-3909",
"expiry": "2019-03"
},
{
"type": "master",
"cardnum": "6274-2542-5847-3949",
"expiry": "2018-12"
}
]](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-18-320.jpg)
![19
N1QL: Data Manipulation Statements
•SELECT Statement-
•UPDATE … SET … WHERE …
•DELETE FROM … WHERE …
•INSERT INTO … ( KEY, VALUE ) VALUES …
•INSERT INTO … ( KEY …, VALUE … ) SELECT …
•MERGE INTO … USING … ON …
WHEN [ NOT ] MATCHED THEN …
Note: Couchbase provides per-document atomicity.](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-19-320.jpg)


![22
N1QL: SELECT Statement Highlights
• Querying across relationships
• INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN (5.5)
• Subqueries
• Aggregation (HUGE PERFORMANCE IMPROVEMENT IN 5.5)
• MIN, MAX
• SUM, COUNT, AVG, ARRAY_AGG [ DISTINCT ]
• Combining result sets using set operators
• UNION, UNION ALL, INTERSECT, INTERSECT ALL, EXCEPT, EXCEPT ALL](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-22-320.jpg)
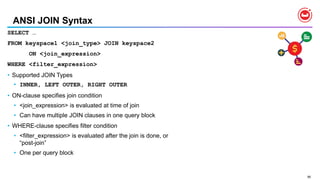
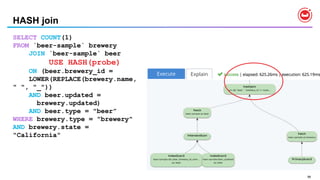
![23
N1QL : Query Operators [ 1 of 2 ]
•USE KEYS …
• Direct primary key lookup bypassing index scans
• Ideal for hash-distributed datastore
• Available in SELECT, UPDATE, DELETE
•JOINs
• INNER, LEFT OUTER, limited RIGHT-OUTER
• Nested loop JOIN is the default
• HASH JOIN for significantly better performance with larger amount of data.
• Ideal for hash-distributed datastore](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-23-320.jpg)
![24
N1QL : Query Operators [ 2 of 2 ]
• UNNEST
• Flattening JOIN that surfaces nested objects as top-level documents
• Ideal for decomposing JSON hierarchies
• Example: Flatten customer document to customer-orders
•NEST
• Does the opposite of UNNEST
• Special JOIN that embeds external child documents under their parent
• Ideal for JSON encapsulation
•JOIN, NEST, and UNNEST can be chained in any combination](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-24-320.jpg)
![25
UNNEST
{
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
]
}
"c": {
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
]
},
"type" : "master",
"cardnum" : "6274-2842-2847-3909”
}
SELECT c, b.type, b.cardnum
FROM customer c
UNNEST c.Billing AS b
"c": {
"Name" : "Jane Smith",
"DOB" : "1990-01-30",
"Billing" : [
{
"type" : "visa",
"cardnum" : "5827-2842-2847-3909",
"expiry" : "2019-03"
},
{
"type" : "master",
"cardnum" : "6274-2842-2847-3909",
"expiry" : "2019-03"
}
]
},
"type" : "visa",
"cardnum" : "5827-2842-2847-3909”
}](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-25-320.jpg)
![26
N1QL : Expressions for JSON
Ranging over collections
• WHERE ANY c IN children SATISFIES c.age > 10 END
• WHERE EVERY r IN ratings SATISFIES r > 3 END
Mapping with filtering • ARRAY c.name FOR c IN children WHEN c.age > 10 END
Deep traversal, SET,
and UNSET
• WHERE ANY node WITHIN request SATISFIES node.type = “xyz” END
• UPDATE doc UNSET c.field1 FOR c WITHIN doc END
Dynamic Construction
• SELECT { “a”: expr1, “b”: expr2 } AS obj1, name FROM … // Dynamic
object
• SELECT [ a, b ] FROM … // Dynamic array
Nested traversal • SELECT x.y.z, a[0] FROM a.b.c …
IS [ NOT ] MISSING • WHERE name IS MISSING](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-26-320.jpg)





























![56
Query Language & Infrastructure
CURL() within N1QL
• CURL (URL, [options])
• The first argument is the URL, which represents any URL that points to a JSON
endpoint.
• Only URLs with the http:// or the https:// protocol are supported.
• Redirection is disabled.
• The second argument is a list of options.
• This is a JSON object that contains a list of curl options and their corresponding
values.
• For a full list of options that we support, please refer to the Dzone article on
CURL in N1QL by Isha Kandaswamy
•](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-56-320.jpg)



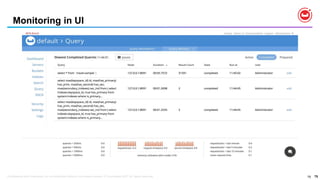
![60
Query Optimizer & Execution: Stable Scans
• IndexScan use to do single range scan (i.e single Span)
• If the query has multiple ranges (i.e. OR, IN, NOT clauses) Query service used
to do separate IndexScan for each range.
• This causes Indexer can use different snapshot for each scan (make it unstable scan)
• Number of IndexScans can grow and result increase in index connections
• In 5.0.0 multiple ranges are passed into indexer and indexer uses same
snapshot for all the ranges.
• This makes stable Scan for given IndexScan (i.e. IndexScan2 in the EXPLAIN).
• This will not make stable scan for query due to Subqueries, Joins etc
• Example:
CREATE INDEX ix1 ON default(k0);
EXPLAIN SELECT META().id FROM default WHERE k0 IN [10,12,13];](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-60-320.jpg)



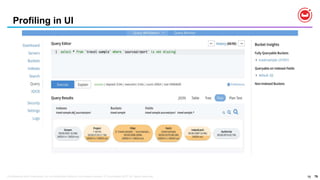
![64
Query Optimizer: Index Projection
• The index can have many keys but query might be interested only
subset of keys.
• By only requesting required information can save lot of network
transportation, memory, cpu, backfill etc. All this can help in
performance and scaling the cluster.
• The requested information can be found in “IndexScan2” Section of
EXPLAIN as “index_projection”
"index_projection": {
"entry_keys": [1, 5 ],
"primary_key": true
}
CREATE INDEX ix1 ON default(k0,k1,k2,k3,k4, k5);
EXPLAIN SELECT meta().id, k1, k5
FROM default
WHERE k0 > 10 AND k1 > 20;](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-64-320.jpg)
![65
Query Optimizer: Index Projection
CREATE INDEX ix1 ON default(k0,k1);
Covered query
SELECT k0 FROM default WHERE k0 = 10 AND k1 = 100;
"index_projection": {"entry_keys": [0,1]}
SELECT k0 FROM default WHERE k0 = 10;
"index_projection": {"entry_keys": [0]}
SELECT k0 ,META().idFROM default WHERE k0 = 10;
"index_projection": {"entry_keys": [0],“primary_key”: true}
Non-covered query
SELECT k0 ,k5 FROM default WHERE k0 = 10 AND k1 = 100;
"Index_projetion": { “primary_key”: true }](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-65-320.jpg)






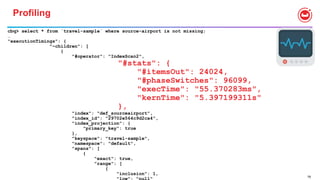
![72
Solution: Intersection
• Option 3
• Too many keys to manage/specify
• The document is flexible. I want the index to be flexible.
CREATE INDEX ixpairon CUSTOMER(DISTINCT PAIRS(self));
SELECT * FROM CUSTOMER WHERE a = 10 and b < 20 and c between 30 and 40;
"#operator": "IntersectScan",
"scans": [
{
"#operator": "DistinctScan",
"scan": {
"#operator": "IndexScan2",
"index": "ixpair",
"index_id": "466c0c5c4c3b21c1",
"index_projection": {
"primary_key": true
},
"keyspace": "test",
"namespace": "default",
"spans": [
{
"exact": true,
"range": [
{
"high": "["a", 10]",
"inclusion": 3,
"low": "["a", 10]"
}
"range": [
{
"high": "["b", 20]",
"inclusion": 1,
"low": "["b", false]"
}
"range": [
{
"high": "[successor("c")]",
"inclusion": 1,
"low": "["c", 30]"
}
]](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-72-320.jpg)

![74
SECURITY : GRANT and REVOKE to roles
• Query_select, query_insert, query_update, query_delete roles
• Parameterized: query_select[customers] or query_insert[*]
• Query_manage_index[foo]
• Create, delete, build indexes on bucket foo
• Query_system_catalog
• Full access to the system tables (which are controlled now)
• Query_external_access
• Allows access to CURL() function (disabled by default)
GRANT cluster_admin TO spock
GRANT query_select ON default TO kirk
REVOKE query_insert, query_delete ON bridge, engineering FROM mccoy, scotty](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-74-320.jpg)













![88
N1QL : Arrays
Array { "hobbies": ["tennis", "skiing", "lego"]}
{ "orders": [582, 9721, 3814]}
Object { "address": {"street": "1, Main street",
"city": Morrisville, "state":"CA",
"zip":"94824"} }
Arrays of objects of arrays [
{
"type": "visa",
"cardnum": "5827-2842-2847-3909",
"expiry": "2019-03"
},
{
"type": "master",
"cardnum": "6274-2542-5847-3949",
"expiry": "2018-12"
}
]](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-88-320.jpg)

![90
Play with ANSI JOIN Support for Arrays - Setup
CREATE PRIMARY INDEX ON product;
"product01", {"productId":
"product01", "category": "Toys",
"name": "Truck", "unitPrice":
9.25}
"product02", {"productId":
"product02", "category":
"Kitchen", "name": "Bowl",
"unitPrice": 5.50}
"product03", {"productId":
"product03", "category":
"utensil", "name": "Spoons",
"unitPrice": 2.40}
CREATE PRIMARY INDEX ON purchase;
"purchase01", {"purchaseId": "purchase01",
"customerId": "customer01", "lineItems": [
{"productId": "product01", "count": 3},
{"productId": "product02", "count": 1} ],
"purchasedAt": "2017-11-24T15:03:22”}
"purchase02", {"purchaseId": "purchase02",
"customerId": "customer02", "lineItems": [
{"productId": "product03", "count": 2} ],
"purchasedAt": "2017-11-27T09:08:37”}](/incomplete_developer/github-https-image.slidesharecdn.com/rio-boss-vldb-couchbase-180827144744/85/Couchbase-Tutorial-Big-data-Open-Source-Systems-VLDB2018-90-320.jpg)











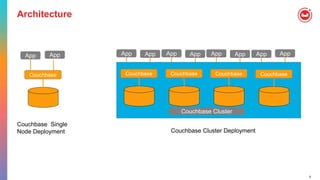
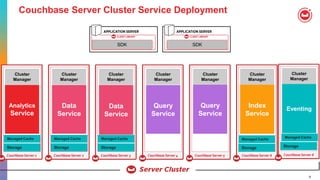
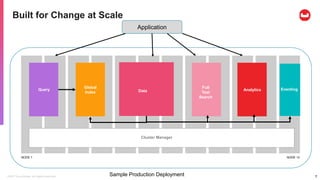
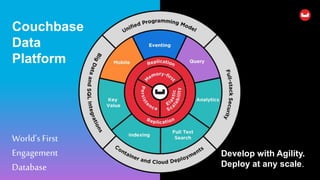
The document provides an agenda and introduction to Couchbase and N1QL. It discusses Couchbase architecture, data types, data manipulation statements, query operators like JOIN and UNNEST, indexing, and query execution flow in Couchbase. It compares SQL and N1QL, highlighting how N1QL extends SQL to query JSON data.







































































