
Not as a gotcha. As a result.
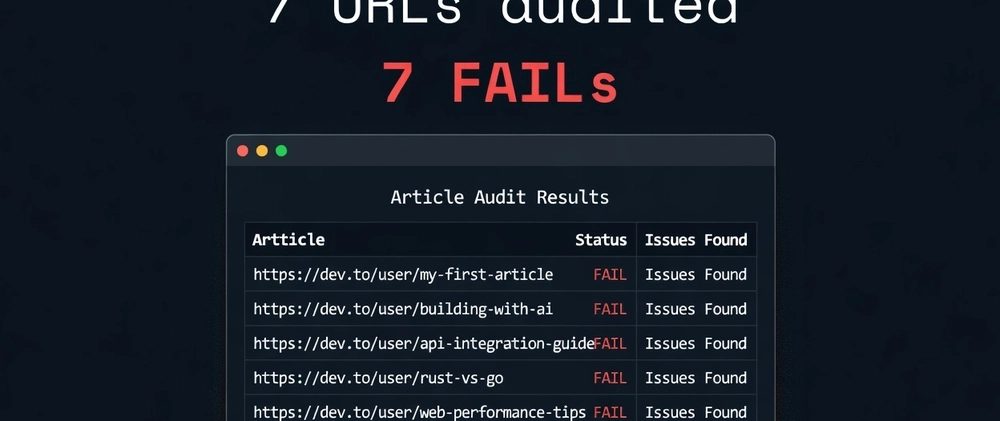
Seven URLs. Seven FAILs.
My Hashnode profile is missing an H1. Three freeCodeCamp tutorials have meta descriptions that are either missing or over 160 characters. Two DEV.to articles have titles too long for Google to render cleanly.
I built the agent. I ran it on my own content first. That's the honest version of the demo.
The problem I was actually solving
Every digital marketing agency has someone whose job is basically this: open a spreadsheet, visit each client URL, check the title tag, check the description, check the H1, note broken links, paste everything into a report. Repeat weekly.
That person costs money. The work is deterministic. The only reason it's still manual is that nobody built the alternative.
I built it in a weekend.
The stack
- Browser Use — Python-native browser automation. The agent navigates real pages in a visible Chromium window. Not a headless scraper. Persistent sessions, real rendering, the same page a human would see.
- Claude API (Sonnet) — reads the page snapshot and returns structured JSON: title status, description status, H1 count, canonical tag, flags. One API call per URL.
- httpx — async HEAD requests for broken link detection. Capped at 50 links per page, concurrent, 5-second timeout per request.
-
Flat JSON files —
state.jsontracks what's been audited. Interrupt mid-run, restart, it picks up exactly where it stopped. No database needed.
Seven Python files. 956 lines total. Runs on a Windows laptop.
The part most tutorials skip: HITL
The agent hits a login wall. Throws an exception. Run dies.
That's most automation tutorials.
This one doesn't work that way.
When the agent detects a non-200 status, a redirect to a login page, or a title containing "sign in" or "access denied", it pauses. In interactive mode: skip, retry, or quit. In --auto mode it skips automatically, logs the URL to needs_human[] in state, and continues.
An agent that knows its limits is more useful than one that fails silently. That's the design decision most people don't make because tutorials don't cover it.
What the audit actually found
I ran it against my own published content across three platforms:
| URL | Failing fields |
|---|---|
| hashnode.com/@dannwaneri | H1 missing |
| freeCodeCamp — how-to-build-your-own-claude-code-skill | Meta description |
| freeCodeCamp — how-to-stop-letting-ai-agents-guess | Meta description |
| freeCodeCamp — build-a-production-rag-system | Title + meta description |
| freeCodeCamp — author/dannwaneri | Meta description |
| dev.to — the-gatekeeping-panic | Title too long |
| dev.to — i-built-a-production-rag-system | Title too long |
The freeCodeCamp description issues are partly platform-level — freeCodeCamp controls the template and sometimes truncates or omits meta descriptions. The DEV.to title issues are mine. Article titles that read well as headlines often exceed 60 characters in the <title> tag.
The agent didn't care. It checked the standard and reported the result.
The schedule play
python index.py --auto
Add a .bat file that sets the API key and calls that command. Schedule it in Windows Task Scheduler for Monday 7am. Check report-summary.txt with your coffee.
That's the agency workflow. No babysitting. Edge cases in needs_human[] for human review. Everything else processed and reported automatically.
What this actually costs
One Sonnet API call per URL. Roughly $0.002 per page. A 20-URL weekly audit costs less than $0.05. The Playwright browser runs locally — no cloud browser fees, no Browserbase subscription.
The whole thing runs on a $5/month philosophy. Same one I use for everything else.
The code
GitHub: dannwaneri/seo-agent
Clone it, add your URLs to input.csv, set ANTHROPIC_API_KEY in your environment, run pip install -r requirements.txt, run playwright install chromium, then python index.py.
The freeCodeCamp tutorial walks through each module — browser integration, the Claude extraction prompt, the async link checker, the HITL logic. Link in the comments when it's live.
The shift worth naming
Browser automation has been a developer tool for a decade. Playwright, Selenium, Puppeteer — all powerful, all requiring someone to write and maintain selectors. The moment a button's class name changes, the script breaks.
This agent doesn't use selectors. It reads the page the way Claude reads it — semantically, through the accessibility tree. A "Submit" button is still a "Submit" button even if the CSS class changed.
The extraction logic is in the prompt, not in the code.
Old way: Automation breaks when the page changes.
New way: Reasoning adapts. The code doesn't need to.
That's the actual shift. Not "AI does the work" but "the brittleness moved." From selectors to prompts. From maintenance to reasoning. The failure modes are different. So is the recovery.
Built this as the first in a series on practical local AI agent setups for agency operations. The freeCodeCamp step-by-step tutorial is coming. Repo is live now.


Top comments (95)
Interesting, but you don't need an LLM for this. Looking at your code, everything you're sending to Claude can be done directly in Python — with two advantages: zero cost, and a fully deterministic approach with no hallucination risk.
You're right that the extraction logic is deterministic — PASS/FAIL on character counts doesn't need a model. But the flags array is where it breaks down. "Title is 67 characters and reads like a navigation label rather than a page description" requires judgment a regex doesn't have. I wanted the output to be actionable, not just binary.
The cost argument holds though. For a pure character-count audit, Haiku at $0.001/URL is already trivial, but zero is less than that.
Where does your Python-only approach handle the ambiguous cases — pages where the title length passes but the content is clearly wrong for the query?
Fair point on the flags — if they're meant to carry semantic judgment ("reads like a nav label"), then yes, a model earns its place. But looking at your schema, the flags are still field-level: "title exceeds 60 characters", not "title is semantically weak". The ambiguous cases you mention — title length passes but content is wrong for the query — aren't in scope here.
That's actually a different tool. A two-pass approach makes more sense: deterministic Python for the binary checks, model call only on pages that pass the mechanical audit but need a second look. You pay per genuinely ambiguous case, not per URL.
The 2-pass framing is better than what I shipped. Deterministic filter first, model only on the survivors — you pay per genuinely ambiguous case, not per URL. That's the right architecture and I didn't build it that way.
The honest reason. I wanted one code path, not two. The added complexity of "run Python, decide if model is needed, run model conditionally" felt like scope creep for a tutorial. In production you're right. In a showcase meant to demonstrate the LLM layer, one pass made the demo cleaner.
Worth a follow-up piece though — "when to add a model to automation that already works."
That's an honest answer — and a better reason than the architecture. "One code path for a tutorial" is defensible; "LLM for character counts in production" isn't.
The follow-up angle is good. Another framing: "the cheapest model that solves the problem" — which sometimes is a regex, sometimes Haiku, occasionally something bigger. Cost and complexity as a sliding scale rather than a binary choice.
is a better frame than 2-pass because it generalizes. Regex → Haiku → Sonnet isn't a decision tree, it's a cost curve. You route based on what the task actually requires not on a predetermined architecture.
The piece writes itself, start with the character count example, work up through cases where Haiku is enough, find the edge where Sonnet earns it. Foundation does something like this implicitly — short queries hit a lighter path but I've never written it out explicitly.
Adding it to the queue.
"Cost curve" is sharper than what I said — I'll use that framing myself. The piece has a natural structure too: character count as the floor, work up to where Haiku plateaus, find the inflection point where Sonnet justifies the delta. Looking forward to reading it.
The inflection point is the piece. Not "use Haiku" or "use Sonnet" — find where the delta stops justifying the cost for your specific task. That's a decision most tutorials skip because it requires running both and measuring, not just recommending.
Glad the cost curve framing travels. I'll tag you when it's up.
Looking forward to it.
The HITL pattern is the most underrated part of this. I run automated SEO audits daily across a large multilingual site (~140K pages, 12 languages) and the biggest lesson was exactly this — the agent needs to know when to stop and flag something for a human instead of silently failing or making up an answer.
The debate in the comments about LLM vs pure Python is interesting. In my experience you need both: deterministic checks for the binary stuff (title length, meta desc present, H1 count, hreflang tags) and the LLM for qualitative judgment calls ("is this title actually descriptive or just keyword-stuffed?"). Running pure regex on 140K pages is cheap but misses the nuance. Running Claude on every page is accurate but expensive. The sweet spot is deterministic first pass → LLM only on the flagged subset.
The $0.002/page cost is solid. At scale that math changes fast though — curious if you've thought about batching the Claude calls or using a cheaper model (Haiku) for the initial classification pass?
The 140K number is where my cost math breaks down fast. At that scale the architecture you described — deterministic first, model on the flagged subset — isn't optional, it's survival. The Haiku question is actually what the follow-up piece became: the cost curve runs regex → Haiku → Sonnet based on what the task requires, and on my last 50-URL run, 8 reached Sonnet. The rest resolved cheaper. Your site would probably produce a different ratio — multilingual with hreflang complexity means more pages that pass binary checks but need semantic judgment. Curious what percentage of your 140K actually reach LLM evaluation on a given run.
the one code path reason thing is probably the most honest part here. seen too many demos where everything works until you pull apart deterministic stuff from the model and then it’s like wait why is the model even here. did the 50 url run change how much of this you’d actually keep in a real system
The 50-URL run answered it. Extraction is pure Python now — title, description, H1, canonical, all deterministic. The model only touches pages where something passes the mechanical check but needs judgment. In production the split is cleaner than I expected and the places where the model still earns it are exactly the messy cases you'd guess: inconsistent templates, third-party injections, content that has to be read rather than located. Wrote up the full architecture here if you want the details: dev.to/dannwaneri/i-was-paying-0006-per-url-for-seo-audits-until-i-realized-most-needed-0-132j
This resonates hard. The deterministic-first approach is exactly what I landed on too. I run automated audits across thousands of pages and the same pattern holds — about 80% of SEO checks are pure string matching and DOM parsing. No model needed.
The messy cases you mentioned (third-party injections, content that has to be read rather than located) — that's where I still lean on the model too. Cookie consent scripts injecting rogue H1 tags, for example. A regex can find the H1 but only the model can tell you "this H1 is from a third-party widget, not your actual page title."
The cost savings from that split are massive at scale. When you're auditing 50+ URLs per run, paying for model inference on every single check would add up fast. Smart architecture. Will check out your full writeup.
The "regex finds the H1, model tells you whose H1 it is" distinction is the cleanest way I've heard it put. That's going in the docs. Glad the writeup is useful — the cost savings at your scale dwarf mine, which is probably why you landed on this architecture before I did.
Exactly right — scale forces you to discover these patterns earlier. When you're running content generation across thousands of pages in 12 languages, you hit the data classification failure case almost immediately. The model produces perfectly grammatical English analysis for a page that's supposed to be in French. Structurally valid, semantically correct, totally wrong audience. No amount of prompt tuning fixes that if the routing layer didn't flag the locale. Looking forward to seeing how you document the regex-then-model split — that framing makes the architecture way more approachable for teams just getting started with content auditing.
The French page with English analysis is the cleanest example of this failure mode I've seen. Structurally valid, semantically correct, entirely wrong and invisible to any check that doesn't read the content. That's the case I want in the documentation because it makes the "why model, not regex" argument without needing to explain the architecture first. The routing layer failure is upstream of the audit entirely, which is the part most teams don't catch until they're already at scale. Working on the write-up — will tag you when it's up.
The regex → Haiku → Sonnet cascade is a really smart architecture. Love seeing someone actually measure the fallthrough rate — 8/50 reaching Sonnet is a useful baseline to plan around.
You're right that multilingual skews the ratio. With 12 locales and hreflang complexity, a lot of my issues are things like English content accidentally rendering on a Japanese page, or hreflang tags pointing to the wrong canonical. Those pass every structural check but fail the semantic "does this page make sense to its intended audience" test. I'd guess 30-40% of my pages would need the LLM tier on any given run, which is exactly why I haven't attempted a full-site audit yet — the cost curve gets steep fast.
30-40% to Sonnet on a full site run is steep, but the number that matters isn't the percentage — it's whether those are the pages that actually need fixing. If hreflang-to-canonical mismatches are concentrated on your highest-traffic locales, a targeted run against that subset costs a fraction of a full audit and surfaces the highest-value issues first. Routing by GSC traffic tier before running the cost curve is the piece I haven't built yet. Have you been able to prioritize which locales or page types to audit first, or is the 89K basically one undifferentiated queue right now?
Great question. We actually do prioritize by locale — GSC gives you impressions by country/language, so you can tier them. English pages get audited first (highest traffic ceiling), then high-impression locales like German and Dutch. The 89K isn't one flat queue — we bucket by page type too (stock detail vs listing vs ETF), since stock pages carry more long-tail value. The cost curve insight is spot on: a targeted run against your top 5 locales × highest-impression page types catches maybe 80% of the real issues at 10% of the full run cost.
The page-type bucketing is the piece I hadn't thought through explicitly. Locale tiering by GSC impressions makes sense, but within a locale, stock detail vs listing vs ETF pages have fundamentally different SEO failure modes — a listing page failing H1 is a different problem than a stock detail page with thin content. Running the cost curve per page type, not just per page, means your Sonnet budget goes to the right class of problem. That's a smarter architecture than mine. I'm adding page-type classification to the roadmap.
Glad the page-type bucketing resonated! You're exactly right that the failure modes are completely different per page type. For us, stock detail pages mostly fail on thin content (the AI analysis needs to be richer), while listing pages fail on technical SEO basics like short meta descriptions and title tags. ETF category pages are a different beast entirely — they need data-driven introductory text blocks to not look like empty index pages.
The cost curve insight is key too. Running a full audit on 100K+ pages is expensive, but if you sample 1 page per type per locale, you catch 80% of the systemic issues because they're template-driven. A bug in the stock detail template affects 8,000 pages — fixing one fixes all of them.
Cool that you're running a similar scale pSEO project. What stack are you using for content generation?
The 1-page-per-template sampling is the insight that should be in the article. Template bugs are the highest-leverage SEO fixes at scale — one fix, 8,000 pages. The cost curve applied to templates means you're not auditing pages at all, you're auditing failure modes. That reframes the whole problem.
For content generation — Cloudflare Workers AI with Vectorize for the RAG layer...
The generation pipeline is the part I've written about separately; the audit agent was built specifically because I needed a way to verify what the pipeline was actually producing at scale, not just what it was supposed to produce. The gap between those two things is where most pSEO quality issues live. What's your generation stack — are the language failures coming from the model or from routing logic upstream?
Great framing — "auditing failure modes, not pages" is exactly right. That 1-page-per-template insight is gold for anyone doing pSEO at scale.
To answer your question about the generation stack: my language failures come from both sides, and the split is instructive.
Model-side failures: I use a local LLM (small 9B parameter model) for content generation across 12 languages. The model sometimes "forgets" the target language mid-generation and reverts to English, especially for less-represented languages. The routing logic sends the right locale, but the model doesn't always comply. This is the biggest quality issue — pages that pass every structural check but have English body text on a Japanese or Hindi page.
Routing-side failures: Some content comes from upstream data sources (like company descriptions from financial APIs) that only exist in English. The routing logic passes these through without translation because they were treated as "data" not "content." Classic case of the pipeline doing exactly what it was told — just not what was intended.
The audit agent catches both, but the fix is different for each. Model failures need prompt engineering or a bigger model. Routing failures need pipeline logic changes. Knowing which is which saves a ton of debugging time.
The model-vs-routing diagnostic split is the part worth writing up separately. Most people debugging language failures assume it's the model — prompt engineer harder, scale up parameters. But if the failure is upstream routing treating source data as pass-through, no amount of prompt engineering fixes it. The audit agent telling you which class of failure you're looking at saves you from spending a week on the wrong layer.
The financial API case is the one I hadn't considered: structured data that's technically correct, comes from a authoritative source, and is completely wrong for its audience because nobody tagged it as translatable content. That's not a model failure or a routing failure — it's a data classification failure that only surfaces when something actually reads the page. Which is exactly why the rendered DOM audit catches it and a structural check never would.
The data classification failure framing is spot on — I'm literally dealing with this exact issue right now. I have a multilingual financial data site where the upstream API (yfinance) returns company descriptions in English regardless of locale. The content is accurate, from an authoritative source, structurally valid — and completely wrong for a French or Japanese audience.
Google's response? Crawled 54K pages and rejected them as low quality. Not because the data was wrong, but because the language classification was wrong. A structural schema check would never catch it. Only a rendered DOM audit that includes language detection per content block would.
You nailed the key insight: knowing which layer failed changes the entire remediation strategy. The fix isn't "better AI content" — it's "route the source data through translation before it reaches the template."
Great work! Hope you are well and it's been awhile.
It is a pain where you mentioned "open a spreadsheet, visit each client URL, check the title tag, check the description, check the H1, note broken links, paste everything into a report. Repeat weekly.". It is very time consuming and glad you made a project that tackle this big issue. Well done! :D
That weekly spreadsheet ritual is the thing nobody talks about when they pitch agency life. Good to hear from you Francis — been a while indeed.
The HITL design is the part that really stands out here. Most agent tutorials treat failure as an edge case — your skip/retry/quit approach treats it as a first-class workflow state. That's a huge difference in production.
I run a similar pattern on my own site (89K+ pages across 12 languages). The SEO audit agent checks GSC data, crawls pages, and files tickets — but the key insight I learned early was exactly what you described: the agent needs to know when it's out of its depth and flag for human review instead of guessing.
On the LLM vs deterministic debate in the comments — I think you nailed the response. The binary checks (title length, meta desc presence) don't need a model. But the qualitative flags ("this title reads like a navigation label") are where the LLM earns its $0.002/page. The hybrid approach is underrated.
Curious about your state.json approach — do you version it or just overwrite? I've found that keeping a rolling history of audit results is useful for tracking whether SEO issues are getting better or worse over time.
89K pages across 12 languages is a different beast entirely . The GSC integration is the piece I deliberately left out of v1 because it changes the architecture. You're not just auditing what's there, you're correlating with what Google sees. That's where the tool gets genuinely useful for agencies and genuinely complex to build.
On state.json — currently just overwrites. Your point about rolling history is the obvious v2. Even a simple append-per-run with a timestamp key would let you track PASS→FAIL regressions over time. That's probably more valuable than the initial audit for most clients.
What does your ticket-filing look like — do you route by severity or just dump everything into a queue?
Severity-based routing, but simplified. The agent categorizes into three buckets: broken (5xx errors, missing hreflang on entire page types, broken JSON-LD), degraded (short meta descriptions, thin content under 200 words), and cosmetic (title slightly over 60 chars, minor formatting). Broken gets a ticket filed immediately in Linear with a DEV- prefix. Degraded gets batched into a weekly ticket. Cosmetic gets logged but no ticket unless it affects a page that's actually ranking.
The key insight was that filing a ticket for every issue creates noise. When I first set it up, the agent generated 40+ tickets in a single run — nobody triages that. Now it deduplicates against existing open issues before creating new ones, which cut ticket volume by about 60%.
The GSC correlation you mentioned is where it gets interesting though. A page can pass every on-page audit but still sit in "crawled - not indexed" for weeks. That's where the tool stops being an auditor and starts being a diagnostic — and that's the harder problem to solve.
The three-bucket system is the right call. Binary pass/fail at scale is just noise with extra steps — the signal is in the severity routing, not the detection.
The deduplication against open issues is the piece I hadn't thought through. Filing a ticket for every run means the same issue gets reopened weekly until someone fixes it. Checking first whether it's already tracked changes the agent from a reporter into something closer to a monitor.
The crawled-not-indexed problem is a different class entirely. On-page signals are visible to the agent. GSC indexing state requires the API, a time dimension, and context the agent doesn't have — why was it crawled, when did status change, what changed on the page between crawl attempts. That's where you stop auditing and start investigating. Have you found a pattern in what actually resolves it, or is it mostly waiting and hoping Google recrawls?
Some patterns have emerged after watching 135K URLs go through the GSC pipeline over 3 months:
Content length matters more than people admit. Pages under 300 words almost never escape "crawled - not indexed." Once I expanded stock page analyses from ~200 to 600-800 words, indexed count jumped 81% in a single week (1,335 → 2,425).
Internal linking is the underrated lever. Adding "Related Stocks" and "Popular in Sector" widgets — basically creating a web of cross-links between stock → sector → ETF pages — seemed to help Google decide individual pages were worth indexing. The pages themselves didn't change, just their connectedness.
Hreflang cleanup had an outsized effect. My "alternate canonical" errors dropped from 682 to 83 after fixing hreflang tags. That correlated with the indexing spike, though causation is hard to prove.
What doesn't seem to work: just waiting. Pages that sat in "crawled - not indexed" for 6+ weeks without any changes rarely moved on their own. The trigger was always a content or structural change that gave Google a reason to re-evaluate.
The content length finding is the most actionable thing in this thread. 81% indexing jump from 200 → 600-800 words is a number worth putting in front of anyone who thinks thin pages are a technical problem rather than a content problem. The agent can flag under-300-word pages trivially — that's a len(text.split()) < 300 check, not a model call...
The internal linking point reframes what the audit should actually measure. Right now the agent checks whether links are broken. What it doesn't check is whether the page is sufficiently connected to the rest of the site. Connectedness isn't an on-page signal — it requires a graph, not a snapshot...
That's the v2 architecture: page-level audit for on-page signals, site-level graph for structural signals. The crawled-not-indexed diagnostic lives in the second layer...
You nailed the v2 architecture framing. The two-layer approach (page-level on-page signals + site-level graph for structural signals) is exactly where this needs to go.
The connectedness metric is something I've been thinking about a lot. Right now the agent catches orphaned pages and broken links, but it doesn't measure things like: how many clicks deep is this page from the homepage? Does every stock page link to its sector page and vice versa? Are there cluster gaps where a whole category of pages has no inbound internal links?
For a site with 89K+ pages across 12 languages, that graph analysis gets computationally interesting fast. But you're right — the crawled-not-indexed diagnostic almost certainly lives in that structural layer. Google isn't going to index a page that's 6 clicks deep with zero internal links pointing to it, no matter how good the on-page content is.
Appreciate the thoughtful breakdown. This is going on the backlog.
The click-depth metric is the one I'd prioritize in the graph layer. Broken links and orphan detection are node-level checks — you can do those without the full graph. Click depth requires traversal from a root, which means you need the graph to exist before you can query it. That's the architectural jump that makes v2 genuinely harder than v1, not just an extension of it.
That's a really sharp distinction — click depth as a graph-level metric vs. broken links as node-level checks. I ran into exactly this when building an internal audit agent for my 89K-page Astro site. The broken link scanner was straightforward (just verify each href resolves), but calculating click depth from the homepage required building a full adjacency map first. Ended up implementing it as a BFS from root, which works but gets expensive fast at scale. Curious — are you building the graph in-memory or persisting it somewhere? At a certain page count, holding the full link graph in memory becomes its own engineering challenge.
Haven't built v2 yet — the graph layer is still on the backlog, so I'm reasoning from first principles rather than production experience here...
That said: at the scale you're describing, in-memory is probably the wrong default. A full adjacency map for 89K pages with 12-language variants means the graph itself becomes the bottleneck before the traversal does. The natural fit is something like SQLite with a self-referencing edges table — persisted, queryable, incrementally updatable as pages change rather than rebuilt from scratch each run. BFS over a SQLite graph isn't as fast as in-memory, but at 89K nodes you're not doing this in real time anyway.
The incremental update problem is the interesting one. Pages get added, removed, relinked. Rebuilding the full graph weekly is expensive. Diffing against the previous run and only re-traversing affected subgraphs is the right architecture but significantly harder to implement correctly.
What's your current rebuild cadence — full graph each run or incremental?
Great question. Right now it's a full rebuild — the entire Astro site regenerates from the database nightly. At ~100K pages across 12 languages, the build itself takes about 45 minutes, and the internal linking is computed fresh each time based on the current stock/sector/ETF relationships in Supabase.
The SQLite edges table idea is really compelling though. Right now the linking logic lives in the Astro build templates (stock pages link to their sector, sector pages list top stocks, ETFs link to related holdings, etc.) so it's declarative rather than graph-traversal based. But if I wanted to do something smarter — like detecting orphaned clusters or optimizing click depth across the whole site — a persisted graph with incremental diffs would be the right architecture.
Honestly haven't hit the pain point hard enough yet to justify the migration, but as the page count grows (especially with TSX/Canadian stocks added recently), I can see it becoming necessary. The rebuild-from-scratch approach has the advantage of being simple and predictable, but it doesn't scale forever.
The declarative linking approach makes sense for the current architecture — the relationships are already in Supabase, the templates just express them. You're not traversing a graph, you're rendering known relationships. That's simpler and predictable, which matters when the rebuild already takes 45 minutes.
The pain point will probably show up as an orphan detection problem before a click-depth problem. Orphans are invisible to the declarative approach — a page that should link somewhere but doesn't requires knowing what the graph should look like, not just what it currently is. That's the gap a persisted graph closes.
TSX/Canadian stocks is the interesting pressure. More pages means more potential orphan clusters, more language variants means more hreflang surface area. The rebuild-from-scratch approach doesn't degrade gracefully — it either works or it takes longer. At some threshold that becomes the constraint.
You nailed the orphan detection issue — that's exactly where the declarative approach breaks down. Right now I'm relying on Supabase relationships (sector → stocks, exchange → stocks) to generate the links, which works for known clusters. But if a stock page exists without a sector assignment or has a stale peer list, nothing catches it. There's no "what should link here but doesn't" check.
The TSX expansion made this real. Going from ~8K to ~10.5K tickers across 12 languages means the rebuild went from manageable to borderline. We're not at the breaking point yet, but I can see it from here. Incremental builds are the obvious answer, but Astro's static output model makes that non-trivial — you'd need to track which pages actually changed at the data level and only rebuild those.
Honestly considering a hybrid approach: keep the full rebuild on a weekly schedule but do incremental deploys for daily price/news updates using a lighter template that skips the cross-linking pass. Trades some link freshness for build speed.
The hybrid approach is the right call at your scale. Full weekly rebuild for structural correctness, incremental daily deploys for data freshness — you're separating two concerns that were previously coupled because the build model forced them together. The tradeoff is explicit and manageable: cross-link freshness lags by up to a week, which matters less than price and news data being stale by a day.
The interesting engineering problem is the change detection layer. "Which pages actually changed at the data level" sounds simple but requires knowing what the page's data dependencies are which for a stock page is price, news, sector assignment, peer list, hreflang variants. Some of those change daily, some change rarely. A dependency graph over the data layer is what makes incremental builds actually incremental rather than just "rebuild less stuff and hope."
That dependency graph is also where orphan detection becomes tractable. A page whose sector assignment was removed shows up as a data change, not a missing link which is a much cleaner signal to act on.
This is exactly why 'human-in-the-loop' is still the most critical part of AI workflows. I've been doing something similar with Next.js 15 dev cycles--building an automated system to catch hallucinations before they hit production. It's fascinating that even when the agent flags everything, the real work is in the systematic prevention of those patterns. Great read on the 'local-first' audit approach!
Hallucination detection before production is the harder version of the same problem — the audit has to be more reliable than the thing it's auditing.
Exactly right — and that is the core tension. My approach shifts the problem: instead of detecting hallucinations after generation, I use .mdc rules to constrain what the model can generate in the first place. It is not perfect but it converts a detection problem into a prevention problem, which is a lot more tractable.
The demo problem is real. Most agent tutorials audit a toy site specifically because it passes cleanly. Running it on your own published work means you can't curate the results — whatever the agent finds is what gets reported. The seven FAILs weren't staged.
Exactly, the real world is messy and that is where these agents usually fall apart. By showing the failures, it's easier to see exactly where the logic breaks down and how to improve the prompts or constraints to handle those edge cases.
Exactly. Hallucination detection before production is the harder version of the same problem - the audit has to be more reliable than the thing it's auditing. This is why I've moved away from "audit-after-the-fact" and more towards "generator-constraints" with .mdc files. If you can force the AI to follow the rule during generation, the audit becomes a lot simpler because you're already within the standard. It's the difference between testing for bugs and formal verification.
Detection-to-prevention is the right reframe. An auditor that runs after generation is always playing catch-up — the cost of fixing a hallucination compounds with how far it traveled before detection...
The .mdc constraint approach is interesting because it moves the enforcement into the generation context rather than a separate validation pass. The analogy to formal verification holds: you're specifying what correct output looks like before the output exists, not checking conformance after.
The limit is expressiveness. Formal verification works cleanly on systems with bounded state. Natural language generation has enough degrees of freedom that constraints leak — the model finds outputs that satisfy the rule syntactically but violate the intent. How are you handling constraint drift as the rules accumulate?
Constraint drift is a huge issue once you cross around 15-20 rules. I've found that grouping them into functional blocks (e.g. 'Data Fetching' vs 'Auth Patterns') and using a 'master' rule to keep the model from trying to satisfy too many competing constraints at once helps. It is definitely a balancing act between precision and flexibility.
The 15-20 rule threshold is useful to know. Below that, individual rules can stay precise. Above it, the model starts satisfying the letter of each rule while violating the spirit of the system which is worse than no rules because it looks compliant.
The master rule as a coherence layer is interesting. You're essentially adding a meta-constraint: satisfy the functional blocks without letting them conflict. That's a second-order problem most people don't hit until the rule count is already too high to untangle easily.
The grouping approach mirrors how you'd structure any constraint system — local rules for local concerns, global rules for cross-cutting concerns. The failure mode is when a local rule has global consequences nobody anticipated.
That second-order problem is exactly what we ran into. Our first attempt at 22 rules had the auth security rule and the middleware rule giving contradictory guidance -- one said 'always check auth server-side' while the other implied middleware was a valid enforcement point. The model would pick whichever it encountered last in context.
The fix was adding an explicit hierarchy: security rules always take precedence over convenience rules. And the project-context rule at the top acts as the coherence layer you described -- it defines the architectural invariants that no other rule can violate.
The Claude Code leak actually validated this approach. Their internal architecture uses a Deny > Ask > Allow permission pipeline with strict evaluation order. Same principle: when constraints conflict, the most restrictive one wins.
The auth/middleware conflict is the canonical example of why constraint ordering matters more than constraint content. Both rules were individually correct — auth should be server-side, middleware is a valid enforcement point. The conflict was in the implicit assumption that they were answering the same question. They weren't. One was about where auth state lives, the other was about where it gets checked.
The Deny > Ask > Allow pipeline is the right mental model for this. It's not just "most restrictive wins" — it's that the evaluation order is explicit and documented, so conflicts surface as design decisions rather than runtime surprises. The model picking whichever rule it encountered last in context is exactly the failure mode that disappears when you make precedence a first-class concern.
The interesting question is whether the hierarchy itself needs rules. At some point the meta-constraints conflict too.
Exactly -- and that is the core tension. My approach shifts the problem: instead of detecting hallucinations after generation, I use .mdc rules to constrain what the model can generate in the first place. It converts a detection problem into a prevention problem, which is more tractable. The rules are just markdown with YAML frontmatter that Cursor reads based on file globs -- so the constraint is injected at generation time.
That is the core challenge. I've found that moving from "natural language instructions" to "strict architectural rules" helps the auditor too. If the auditor knows the codebase must follow a specific pattern (like awaiting all params in Next.js 15), then the audit becomes binary rather than subjective.
Love this. There's something genuinely useful about using the same tool to audit the work it helped you produce - catches the patterns you've normalized. Curious what the most common flag was. Was it style/tone or more structural things like missing context or weak conclusions?
Mostly structural — missing meta descriptions, titles over 60 characters, H1 count issues. Nothing about style or tone because the agent isn't reading for quality, it's checking against standards. The interesting case was freeCodeCamp's own template truncating descriptions on article listing pages — the agent flagged it as a FAIL and it technically is, even though it's platform-level and outside my control. Auditing your own work with your own tool finds the things you'd rationalized as acceptable.
The structural stuff makes sense - those are measurable so the agent can actually flag them. But that freeCodeCamp case is the interesting one. Platform-imposed truncation showing up as a personal FAIL is exactly the kind of thing you'd normally just rationalize away. The agent doesn't know context, so it flags it anyway. Weirdly that's the most honest kind of audit.
Context-free is the feature not the limitation. A human auditor would see "freeCodeCamp template" and mark it acceptable. The agent sees a missing meta description and marks it FAIL. Both are correct . they're answering different questions.
The agent answers: does this page meet the standard? The human answers: is this worth fixing given the constraints? You need both. The agent's job is to surface everything. Your job is to triage what actually matters.
The platform-imposed FAIL is useful precisely because it forces the triage decision to be explicit rather than assumed. You either fix it, escalate it, or document why it's acceptable. Any of those is better than normalizing it silently.
The agent/human split you're describing is exactly right. The agent answers "does this meet the standard" - the human answers "is this worth fixing given the context". Those are genuinely different questions and both useful. The platform-imposed failures are actually good signal - they're showing you the gap between your setup and the standard, even if you consciously chose that gap.
is the useful distinction. There's a difference between a FAIL you didn't know about and a FAIL you accepted. The agent can't tell which is which but surfacing both forces you to be explicit about which category each one falls into. The ones you assumed were acceptable without ever deciding they were is where the audit earns its cost.
Yeah exactly - the ones you assumed were fine without deciding they were is the honest gap. Surfacing it is most of the value.
Surfacing it is most of the work. The deciding is faster once you can see it clearly.
Exactly. The decision is quick once you stop rationalizing.
"It flagged every single one" is a satisfying result in a perverse way — it means the audit is actually working rather than being sycophantic. Self-critique tools that only flag obvious problems quickly become noise that you tune out. The ones that surface genuine issues in work you thought was solid are the ones worth keeping.
The interesting design question for a writing auditor is what dimensions to evaluate — clarity, factual accuracy, logical consistency, missing context, tone — because the failure modes are very different and some are more automatable than others. Factual claims and structural logic are relatively easy for an LLM to flag; things like "is this actually useful to the intended reader" are much harder because they require modeling the reader's specific knowledge state.
What were the most common categories of issues it surfaced? I'm curious whether the flags were mostly stylistic or whether it caught substantive gaps in the reasoning.
The flags were almost entirely structural, not substantive which is both honest and limiting. Missing meta descriptions, titles over 60 characters, absent canonicals. The agent found what was technically wrong, not what was argumentatively weak. "This title is 67 characters" is a different class of finding than "this piece buries the actual insight in paragraph four."
The dimension you're pointing at — is this actually useful to the intended reader — is the one I haven't touched yet, and probably can't with the current architecture. Modeling a reader's knowledge state requires knowing who the reader is, which the agent doesn't. What it can do is flag when the structure makes the useful part hard to find. That's a narrower version of the same problem, but it's automatable. The substantive gaps are still a human job.
This is good. I like how you tested it on your own work instead of just using it on a demo. That makes it more real. I also like how you included HITL, as most people would skip this part and their script would just break.
The demo problem is real. Most agent tutorials audit a toy site specifically because it passes cleanly. Running it on your own published work means you can't curate the results whatever the agent finds is what gets reported. The seven FAILs weren't staged.
This is one of the more nuanced discussions I've seen on AI tooling. The "cost curve" framing Pascal and Daniel landed on is exactly the right mental model — not every task needs the same level of intelligence, and the real engineering challenge is routing to the cheapest model that solves the problem at each step.
I'd add that this pattern extends beyond content auditing. In production AI systems, we often see a tiered approach: deterministic rules first, lightweight models for triage, and larger models reserved for genuinely ambiguous edge cases. It keeps latency low, costs predictable, and reduces unnecessary LLM dependency.
Looking forward to the follow-up on finding that inflection point — measuring where the cost delta stops justifying the upgrade is something most teams skip but is critical for sustainable AI adoption.
The 3-tier pattern is the production version of what Pascal and I landed on in the abstract. Deterministic rules → lightweight triage → frontier model for edge cases maps directly to the cost curve: floor, middle, and the inflection point where the upgrade justifies itself.
The latency argument is the one I hadn't foregrounded. Cost is measurable upfront. Latency compounds in ways that aren't obvious until you're watching a 7-URL audit take 4 minutes because every page hits Sonnet regardless of complexity. Routing by task type fixes both problems simultaneously.
The follow-up piece has a natural structure now — build the three tiers explicitly, measure where each plateau hits, find the inflection empirically rather than guessing. That's a more useful article than
Solid architecture, Daniel. The use of flat JSON for state persistence is a smart move for local agents—keeps things portable and debuggable without the overhead of a database. It’s also interesting to see how Claude handles the accessibility tree instead of raw HTML. Definitely a more resilient way to build scrapers/auditors today.
The accessibility tree point is worth expanding on. Raw HTML gives you structure — the accessibility tree gives you intent. A div styled to look like a button is invisible to a scraper. Browser Use sees it the same way a screen reader would. That shift from parsing markup to reading meaning is what makes the extraction prompt reliable across different site architectures.
Some comments may only be visible to logged-in visitors. Sign in to view all comments.