
How ULID Actually Works: Implementing the Codec in 60 Lines of Python
A scriptable ULID CLI — new, parse, monotonic, validate — with zero dependencies. The codec is hand-written and the whole point of the article.
If you've started any new backend in the last few years, chances are you've reached for a ULID somewhere. ULIDs are the quiet default now: 128 bits of ID, 48 bits of timestamp, 80 bits of randomness, 26 characters, lexicographically sortable, shorter than a UUID, and — critically — readable enough that you can paste one into a Slack thread without eyes glazing over. Shopify uses them. Planetscale suggests them. Every "alternative to UUID v4" blog post you've read in the last three years was really a pitch for either ULID or UUID v7, which are almost the same thing in slightly different hats.
What's surprisingly missing is CLI tooling. Every ULID library I've looked at is gorgeous — bindings for Python, Go, Node, Rust, Postgres extensions — but if you're at 2 a.m. debugging a distributed trace and you've got a ULID in your terminal, you still need to open a REPL to find out when it was created. That's backwards. ULID's entire selling point is being human-friendly. The tooling should match.
So I wrote one. ulid-cli is a stdlib-only Python CLI that generates, parses, validates, and round-trips ULIDs. Zero runtime dependencies. The Crockford base32 codec and the monotonic-generation trick are implemented from scratch in about 60 lines. This article is mostly about those 60 lines, because once you've written them, you understand ULID — and that understanding generalizes to UUID v7, KSUID, and anything else in the "sortable ID" family.
GitHub: https://github.com/sen-ltd/ulid-cli
The spec in one paragraph
A ULID is a 128-bit identifier. The top 48 bits are a Unix-millisecond timestamp (big-endian unsigned int, so the year 10889 is your cutoff). The bottom 80 bits are random. You encode the whole thing as 26 characters of Crockford base32 — an alphabet chosen so that each character carries exactly 5 bits (32 symbols = 2^5), giving you 26 × 5 = 130 bits to work with, just barely enough for 128. The first character of a ULID can only meaningfully carry 3 bits, since the other 2 are always zero.
And that's it. Once the timestamp is in the high bits and the alphabet is in ASCII order, string comparison agrees with chronological order for free. You can ORDER BY id on a ULID column and get creation-time ordering with no extra indexes. That is the entire trick, and it's worth internalizing because UUID v7 and KSUID both do the same thing with different bit widths.
Designing the layout
Here's the concrete layout in one picture:
0 48 128
├───── timestamp ────┤├──── randomness ───┤
│ 48 bits (big-end) ││ 80 bits │
│ Unix ms since epoch│ from secrets │
└────────────────────┘└──────────────────┘
│
base32 encode
│
▼
01KP7RTPGZ B62RC63XPYZENR1F
└───ts────┘└─────randomness─┘
10 chars 16 chars
The 48-bit timestamp gives you milliseconds resolution up to the year 10889, which is probably fine for anything you're building. The 80 bits of randomness give you a collision probability of roughly 1 in 2^80 within a single millisecond, which is also probably fine — that's about 10^24 generations in the same ms before you'd start worrying.
Crockford base32 and the alphabet hack
A naïve base32 alphabet would be ABCDEFGHIJKLMNOPQRSTUVWXYZ012345 or something similar. Douglas Crockford pointed out that this collides badly with human handwriting: I and 1 and l look identical in most fonts, O and 0 are famously confusable, and U looks enough like V to cause problems when someone reads a ULID aloud. His alphabet is:
0123456789ABCDEFGHJKMNPQRSTVWXYZ
That's 0-9 followed by A-Z with I, L, O, U removed. 26 letters + 10 digits − 4 excluded = 32 symbols. It's 5 bits per symbol, same as any base32 alphabet, but now a human who handwrites a ULID on a whiteboard can transcribe it back into a terminal with materially fewer errors. When decoding, you accept I/L as aliases for 1 and O as an alias for 0, so the transcription is even more forgiving. U is reserved as "explicitly rejected" — if you see one, the input is wrong, not ambiguous.
Here's the encoder. The whole thing:
CROCKFORD_ALPHABET = "0123456789ABCDEFGHJKMNPQRSTVWXYZ"
def encode(timestamp_ms: int, randomness: bytes) -> str:
if timestamp_ms < 0 or timestamp_ms > (1 << 48) - 1:
raise ValueError(f"timestamp {timestamp_ms} out of 48-bit range")
if len(randomness) != 10:
raise ValueError(f"randomness must be 10 bytes, got {len(randomness)}")
# Pack into a single 128-bit integer: timestamp in high bits, randomness low.
rand_int = int.from_bytes(randomness, "big")
full = (timestamp_ms << 80) | rand_int
# Emit 26 chars, most-significant first. 26 * 5 = 130 bits; the top
# 2 bits of the first char are always zero because the value is 128 bits.
out = [""] * 26
for i in range(25, -1, -1):
out[i] = CROCKFORD_ALPHABET[full & 0x1F]
full >>= 5
return "".join(out)
That's fifteen lines including the error checks, and there isn't a single external call. Python's arbitrary-precision integers make this trivial: (timestamp << 80) | randomness gives you a genuine 128-bit number, no BigInt library or struct juggling. The loop peels 5 bits at a time off the bottom and writes them from the end of the output buffer backwards. Done.
Decoding is the same operation run in reverse, with one wrinkle worth calling out:
def decode(ulid: str) -> tuple[int, bytes]:
if len(ulid) != 26:
raise ValueError(f"ulid must be 26 chars, got {len(ulid)}")
# The first char can only carry 3 bits of real value (0-7) because
# the whole integer is 128 bits, not 130. Reject anything larger:
# "8000...0" would decode to a 129-bit number, which isn't a ULID.
first = _DECODE.get(ulid[0])
if first is None:
raise ValueError(f"invalid character {ulid[0]!r}")
if first > 7:
raise ValueError(f"first character overflows 128-bit space")
full = 0
for i, ch in enumerate(ulid):
v = _DECODE.get(ch)
if v is None:
raise ValueError(f"invalid character {ch!r} at position {i}")
full = (full << 5) | v
timestamp_ms = (full >> 80) & ((1 << 48) - 1)
rand_int = full & ((1 << 80) - 1)
return timestamp_ms, rand_int.to_bytes(10, "big")
The wrinkle is the "first character ≤ 7" check. 26 base32 characters can represent 130 bits, but a ULID is only 128 bits, so the top 2 bits must be zero. In practice that means the first character, which encodes bits 125–129, can only carry the 3 low bits of its 5-bit slot — meaning its value must be 0–7. If you see a ULID starting with 8 or higher, it isn't a valid ULID at all; it's an overflowed encoding. The ULID spec calls this out explicitly, and it's the easiest place to miss a correctness bug. I caught it because of the test that asserts decode("8" + "0" * 25) raises.
The monotonic trick
Here's the interesting one. Two ULIDs generated in the same millisecond have the same 48-bit prefix. Their order then depends entirely on their random tails, which by construction are independent — so you have a 50/50 chance of the "second" ULID sorting before the "first" one. For a format whose selling point is sort-by-creation-time, that's a real foot-gun.
The spec's fix is the monotonic guarantee: within the same millisecond, reuse the previous randomness and add 1 to it, treating the 80 bits as a big-endian unsigned integer. The second ULID in a ms is prev + 1, the third is prev + 2, and so on. Because base32 encodes big-endian and the alphabet is in ASCII order, incrementing the bytes by 1 increments the string by 1 too — you preserve lex order automatically.
def increment_randomness(randomness: bytes) -> bytes:
n = int.from_bytes(randomness, "big")
if n == (1 << 80) - 1:
raise OverflowError("randomness overflow in same millisecond")
return (n + 1).to_bytes(10, "big")
def monotonic_batch(n: int, clock, rand) -> list[str]:
out = []
last_ts = -1
last_rand = b""
for _ in range(n):
ts = clock()
if ts == last_ts:
last_rand = increment_randomness(last_rand)
else:
if ts < last_ts:
# Clock went backwards. Pin to last_ts to preserve order.
ts = last_ts
last_rand = increment_randomness(last_rand)
else:
last_ts = ts
last_rand = rand(10)
out.append(encode(ts, last_rand))
return out
Two gotchas hiding in those 15 lines:
-
Clock regression. NTP is allowed to step the clock backwards. If that happens mid-batch, the naïve implementation emits a ULID whose timestamp is earlier than the previous one, and your "monotonic" guarantee is dead. The fix is to pin
tsto the last-seen timestamp and increment the randomness instead. This is what the ULID spec calls "frozen time" handling, and most libraries get it right but it's easy to forget if you write your own. -
Randomness overflow. If you generate 2^80 ULIDs in the same millisecond, the randomness wraps around. You'll never hit this in practice, but the spec says to raise rather than silently wrap, and so do we. It's one
if.
The acceptance test I care about most is: generate 1000 monotonic ULIDs with a fixed clock, shuffle them, sort them, assert you got the original list back. If that passes, the monotonic guarantee actually holds. This is the test that caught a real bug in an earlier draft where I was re-drawing randomness on every call even in the same millisecond (I had the if ts == last_ts check but was still calling rand(10) unconditionally underneath). The strict-sort test failed immediately. Without that test I probably would have shipped it.
Sortability is not a happy accident
People sometimes describe ULID's sortability as "an emergent property of putting the timestamp first." That's half right. The timestamp prefix gets you most of the way there — but the alphabet choice is doing work too. Consider what would have happened with a different 32-character alphabet, say abcdefghijklmnopqrstuvwxyz012345. Then '0' (ASCII 0x30) sorts after 'z' (ASCII 0x7A), because ASCII digits come before lowercase letters in the ordering. Strings encoded with that alphabet wouldn't sort the same way as the underlying integers. You'd get timestamp-order for free if you were lucky and broke it if you weren't.
Crockford's alphabet dodges this because it's 0-9A-Z in ASCII order, with the confusing letters removed. Each character's ordinal matches its numeric value. 26 characters encoded most-significant-first gives you, by construction, a string whose lexicographic order matches the integer's numeric order, which matches chronological order. It only works if all three orderings agree, and they only agree because someone picked the alphabet carefully.
KSUID makes a different (and I'd argue worse) choice: 0-9A-Za-z base62, which also happens to be in ASCII order but is much harder to decode cleanly and requires a bignum multiplication loop instead of bit shifts. If you've ever wondered why KSUID libraries all ship with a custom base62 implementation, that's why.
Comparison with UUID v7 and KSUID
UUID v7 (RFC 9562, published May 2024) does nearly the same thing as ULID: 48 bits of Unix-ms timestamp, then 74 effective bits of randomness (the rest is version/variant metadata). It's encoded as a 36-character UUID with dashes, which is strictly worse for ergonomics but vastly better for compatibility with every database, ORM, and framework that already understands UUIDs. If you're building a new system and your stack happily swallows UUIDs, v7 is probably the right default. If you want shorter strings and don't mind being the weird one in the PR review, use ULID.
KSUID goes the other direction: 32-bit second-resolution timestamp (no millis), 128 bits of randomness, base62-encoded to 27 characters. Segment picked it for a pipeline where they generate billions of events per day and care more about randomness than about millisecond ordering. For most of us it's overkill, and the second-resolution timestamp means all events in a given second have undefined ordering relative to each other.
The rule of thumb I actually use:
- Need to store in an existing UUID column? UUID v7.
- Greenfield, want shorter URLs? ULID.
- Billions of events per second per shard? KSUID, and go talk to Segment's infra team about event fanout.
- Don't need ordering at all? UUID v4 is still fine. The database isn't slow because of your ID format.
Tradeoffs
Before you rush to replace every UUID v4 in your system, the ULID family has real downsides you should know about:
The timestamp is visible. If your ID is public-facing and the creation time is sensitive, ULID leaks it. A URL slug of /orders/01KP7RTPGZB62RC63XPYZENR1F tells anyone that order was created at 2026-04-15T05:11:38Z. That's fine for most backend systems but problematic for user-facing ID-as-URL patterns where you want pseudonymity. UUID v4 gives you nothing of the sort.
Clock regression breaks monotonicity. As mentioned above, you can work around it — pin to the last timestamp and increment — but only within a single process. Two processes generating "monotonic" ULIDs independently will interleave in unpredictable ways if their clocks disagree by more than a few ms. ULID's monotonic guarantee is a process-local property, not a distributed one.
80 bits of randomness is less than UUID v4's 122. In practice it doesn't matter — you need 2^40 same-ms generations to hit a ~50% collision probability by the birthday bound, and nobody does that. But if you're paranoid or required to meet a specific cryptographic threshold, the lower-entropy tail is worth knowing about.
No native database support. Postgres will happily store a ULID as text, but you lose the uuid type's fixed-16-byte storage and B-tree optimizations unless you install a ULID extension. This is the single biggest reason UUID v7 is the pragmatic choice for most teams.
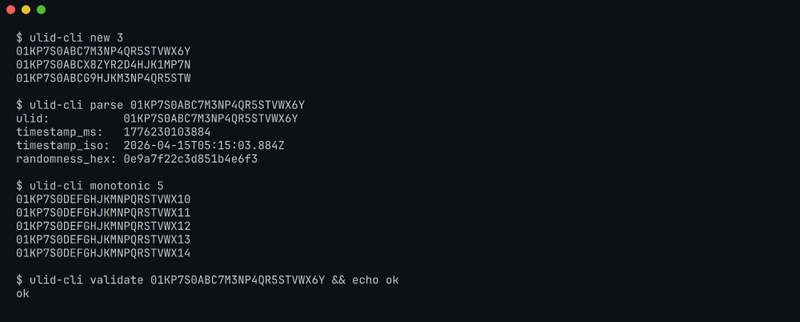
Try it in 30 seconds
git clone https://github.com/sen-ltd/ulid-cli
cd ulid-cli
docker build -t ulid-cli .
docker run --rm ulid-cli new 3
# 01KP7S0ABC7M3NP4QR5STVWX6Y
# 01KP7S0ABCX8ZYR2D4HJK1MP7N
# 01KP7S0ABCG9HJKM3NP4QR5STW
docker run --rm ulid-cli parse 01KP7S0ABC7M3NP4QR5STVWX6Y --format json
docker run --rm ulid-cli monotonic 10
# 10 ULIDs, guaranteed strictly increasing
docker run --rm ulid-cli from-time 2026-04-15T00:00:00Z 5
# 5 ULIDs pinned to midnight UTC
docker run --rm ulid-cli validate 01KP7S0ABC7M3NP4QR5STVWX6Y && echo valid
The image is about 60 MB (alpine + Python + zero third-party code). Tests run in the container too:
docker run --rm --entrypoint pytest ulid-cli -q
# 47 passed in 0.06s
47 test cases covering the codec, the monotonic guarantee under 1000 same-ms calls, clock regression handling, every output format, and exit codes. The monotonic strict-ordering test is the one I'd want a reviewer to single out: generate 1000, shuffle, sort, assert equal to the original list. If that ever fails, the whole tool is a lie.
Closing
The whole thing is about 60 lines of ULID-specific code (codec + monotonic generator) wrapped in an argparse CLI. No runtime dependencies. Writing it out yourself once is worth any number of blog posts, because now when someone asks "why ULID over UUID v7?" you have an actual answer instead of a vibe.
Entry #118 in a 100+ portfolio series by SEN LLC. Related previous entries:
- id-generator — web-based UUID v4/v7, ULID, NanoID, KSUID generator with the same "write it yourself" spirit
- har-analyze — another zero-deps Python CLI in the same house style
Feedback welcome.


Top comments (0)