
Counting Moras: Why Your 5-7-5 Haiku Validator is Probably Wrong
A small Python CLI that validates Japanese haiku against the 5-7-5 mora pattern — and a crash course in the Japanese phonology that makes "just count the syllables" the wrong answer.
Every English explanation of haiku you have ever read begins with the same sentence: "A haiku has five syllables, then seven, then five." It is a satisfying piece of folk wisdom, it is the version they teach in elementary school, and it is wrong in a way that makes every beginner who tries to write Japanese verse write something that doesn't scan.
Japanese doesn't count syllables. It counts moras (拍, haku), a smaller unit, and once you internalize what a mora is and isn't, the whole structure of Japanese poetry clicks into place. The difference matters enough that I built a small CLI to enforce it.
haiku-score is a zero-dependency Python tool that validates kana text against a mora pattern. The default pattern is 5-7-5, there is a --tanka shorthand for 5-7-5-7-7, and you can pass any comma-separated pattern with --pattern. It reads from a file, from stdin, or from an inline argument. The entire core — the mora counter — is about 50 lines of standard-library Python, and every one of those lines is making a specific decision about Japanese phonology.
This article is about what those decisions are, why the syllable-counting approach fails, and one interesting scope discipline choice: haiku-score refuses kanji input on purpose, and I think that was the right call.
GitHub: https://github.com/sen-ltd/haiku-score
What a mora actually is
A mora is a timing unit. In Japanese, every mora takes roughly the same amount of time to pronounce, and this is the unit that the 5-7-5 structure counts. It is slightly shorter than a typical English syllable, and the edge cases are where things get interesting.
Here is the rule in 30 seconds:
- Each full-size kana character (ふ, る, い, カ, タ) = 1 mora.
- A small ゃ, ゅ, ょ attached to a preceding kana fuses with it to form a youon (拗音) — the combined pair is 1 mora, not 2. So きゃ is 1 mora and きよ is 2.
- The long-vowel mark ー = 1 mora. It extends the previous vowel by one full beat. コーヒー is 4 moras: コ・ー・ヒ・ー.
- The small っ (sokuon, 促音) = 1 mora. It represents a beat of silence before the next consonant. にっぽん is 4 moras: に・っ・ぽ・ん.
- The character ん (hatsuon, 撥音) = 1 mora. ほん is 2 moras, not 1.
- Whitespace and punctuation are 0 moras.
That's it. That is the entire phonology of mora counting. And every single one of those rules breaks the "just count the kana characters" approach in some way.
Where syllable counting goes wrong
Let me make this concrete. Take the word 東京 — Tōkyō, the capital of Japan. How many "syllables" is it?
If you are an English speaker, you probably say "two: To-kyo." That is the intuition syllable-counting gives you.
But in Japanese, 東京 is pronounced とうきょう, and it is 4 moras: と・う・きょ・う. Each one is a distinct beat, and when Japanese speakers fit とうきょう into a haiku, they use 4 of the 17 beats available.
Or take Nippon — 日本, にっぽん. English speakers naturally say "Nip-pon" and count 2 syllables. Japanese counts 4: に・っ・ぽ・ん. The small っ is a full beat, a moment of silence before the p. If you tried to write a haiku using にっぽん and counted it as 2 "syllables", your poem would be three beats short.
The word ramen, ラーメン, is 4 moras (ラ・ー・メ・ン), not 2. The long mark ー is its own beat. The word ホテル (hotel) is 3 moras, which matches the English "ho-tel" if you squint, but ノート (notebook) is 3 moras (ノ・ー・ト), not 2.
Once you have counted enough of these, the pattern becomes obvious: English syllable counting and Japanese mora counting sometimes agree, but the places where they disagree are the places where the 5-7-5 structure will feel broken to a Japanese ear. A tool that just calls len(string) or splits on whitespace will get most of them wrong.
The counting loop
The heart of haiku-score is a single function, count_moras, that walks the string character by character and tracks state:
def count_moras(text: str) -> int:
total = 0
previous_was_full_kana = False
for i, ch in enumerate(text):
if classifier.is_ignored(ch):
previous_was_full_kana = False
continue
if classifier.is_long_mark(ch):
total += 1
previous_was_full_kana = False
continue
if classifier.is_small_yoon(ch):
# Fuse into the previous full kana: it already contributed 1
# mora, and this small ゃ contributes 0.
previous_was_full_kana = False
continue
if classifier.is_sokuon(ch):
total += 1
previous_was_full_kana = False
continue
if classifier.is_hatsuon(ch):
total += 1
previous_was_full_kana = False
continue
if classifier.is_kana(ch):
total += 1
previous_was_full_kana = True
continue
if classifier.is_kanji(ch):
raise MoraError(ch, i, "kanji")
raise MoraError(ch, i, "unknown")
return total
That's it. Six ifs and a running total. The whole algorithm is: every character adds 1 to the total unless it's a small youon (which subtracts the 0 by being ignored — the previous character already added its 1) or it's punctuation (also ignored). Long marks, sokuon, and hatsuon each add 1 as their own beat.
The previous_was_full_kana flag exists for a single edge case: a bare small ゃ at the start of a line. In that position there is no preceding full kana to fuse with, so we count it as 0 rather than erroring. Degenerate input shouldn't crash the tool.
Unicode ranges as the classifier
Every character classifier in haiku-score is a one-liner that checks codepoint ranges. There is no dictionary lookup, no third-party library, nothing. This works because the kana blocks in Unicode are well-defined and contiguous:
_HIRAGANA_START = 0x3040
_HIRAGANA_END = 0x309F
_KATAKANA_START = 0x30A0
_KATAKANA_END = 0x30FF
_LONG_MARK = 0x30FC # ー
def is_hiragana(ch: str) -> bool:
return len(ch) == 1 and _HIRAGANA_START <= ord(ch) <= _HIRAGANA_END
def is_long_mark(ch: str) -> bool:
return len(ch) == 1 and ord(ch) == _LONG_MARK
The small kana are enumerated as literal frozensets because they are not contiguous in the block — they are interleaved with their full-size counterparts. But listing them is fine, there are only about a dozen:
_SMALL_HIRAGANA = frozenset("ぁぃぅぇぉゃゅょゎ")
_SMALL_KATAKANA = frozenset("ァィゥェォャュョヮヵヶ")
_SMALL_KANA = _SMALL_HIRAGANA | _SMALL_KATAKANA
def is_small_yoon(ch: str) -> bool:
return ch in _SMALL_KANA
The entire classifier module is 80 lines and has no imports except __future__. This is the sort of problem that makes you grateful Unicode actually did the work of putting the blocks in sensible places.
The kanji error, with position
When haiku-score sees a kanji character — or any character it doesn't recognize — it raises a MoraError that carries the position of the offending character:
class MoraError(ValueError):
def __init__(self, char: str, position: int, reason: str) -> None:
self.char = char
self.position = position
self.reason = reason
if reason == "kanji":
msg = (
f"kanji {char!r} at position {position}: haiku-score counts "
f"moras on kana input. Convert kanji to kana first "
f"(e.g. with pykakasi, or your own lookup) then re-run."
)
else:
msg = (
f"unknown character {char!r} (U+{ord(char):04X}) at position "
f"{position}: expected hiragana, katakana, ー, or punctuation."
)
super().__init__(msg)
The CLI layer maps this to exit code 2 and prints the message to stderr. The point of including the position isn't so you can programmatically find the character — it's so a user with a long input can see where their problem is. If you have 300 characters of pasted text and one stray kanji hidden in the middle, "position 147" is dramatically more useful than "kanji found".
The scope discipline call: no kanji-to-kana conversion
Here is the decision I want to defend. haiku-score does not convert kanji to kana. If you pass 古池や, you get an error.
The obvious complaint is that this makes the tool less useful. Real Japanese text — haiku included — is written in a mix of kanji and kana, and a tool that refuses real-world input is a toy. A senior reviewer looking at this might reasonably ask: why not just pipe through pykakasi internally?
Three reasons.
First, kanji-to-reading is not a trivial function. The character 日 is read ひ in 日曜日 (に・ち・よ・う・び), にち in 二月三日 (に・が・つ・み・っ・か — and notice the unpredictable み・っ・か for 三日), and じつ in 休日 (きゅ・う・じ・つ). Getting this right requires either a full morphological analyzer (MeCab, Sudachi, Fugashi) plus a pronunciation dictionary, or a statistical model trained on labelled data. Either way, you're now shipping dozens of megabytes of resources and pulling in large third-party dependencies.
Second, the entire thesis of the project is that the core algorithm is small and transparent. The mora counter is 50 lines and uses only the standard library. If I bolt a kanji reader onto the front of it, the mora counter becomes an afterthought buried inside a much bigger, murkier system. Users who want to understand how mora counting works — which is half the point of releasing the tool — now have to wade through a dictionary lookup layer to get there.
Third, the right place for kanji-to-kana is a separate tool in a separate process. Unix pipes exist precisely for this. You can run your kanji text through pykakasi (or MeCab, or whatever converter you prefer) and pipe the output into haiku-score:
echo "古池や蛙飛び込む水の音" | python -c "
import sys, pykakasi
kks = pykakasi.kakasi()
for line in sys.stdin:
print(''.join(item['hira'] for item in kks.convert(line.strip())))
" | haiku-score -
This is actually better than integrating them, because the user gets to pick their converter. Different Japanese text needs different tools — classical poetry uses different readings than modern prose, and specialised dictionaries beat general-purpose ones for specific genres. haiku-score trusting the input to already be kana is a feature: it means the user is in control of the hard problem, and the tool they run afterwards is small, fast, inspectable, and correct about the part it does handle.
This is scope discipline, and it matters more than feature completeness. The things haiku-score does, it does well, and the error message when it meets kanji tells you exactly what tool you want next.
Tradeoffs I'm making
Let me be honest about where this approach breaks.
Real-world text is mixed script. Most haiku in the wild are written with some kanji and some kana. A tool that requires all-kana input is strictly less convenient than one that handles mixed script. If your workflow is copying haiku from a book and pasting them into a CLI, you will find haiku-score annoying. You either do the conversion yourself (ergonomic cost), pipe through another tool (setup cost), or use a different validator.
Pronunciation ambiguity. Even within kana, there are cases where the "correct" mora count is ambiguous. The particle は is normally 1 mora (the kana for ha), but it's pronounced wa when it's functioning as a particle — still 1 mora, so we're fine. But consider words written with historical kana spellings where the orthography and pronunciation differ: we count the orthography, not the pronunciation, which means a few edge cases in classical poetry might come out different from what a purist would say. For practical modern haiku, this doesn't matter. For scholarly work on Man'yōshū, you'd want something more sophisticated.
Dialectal variation. Standard Japanese mora counting assumes standard-dialect pronunciation. Kansai-ben, Tohoku-ben, and Okinawan all have different prosodic patterns. haiku-score, like essentially every written-form tool, assumes standard Tokyo-dialect timing. This is fine for 99% of users and wrong in interesting ways for linguists.
The small-kana-at-start case. A bare ゃ at the start of a line isn't a mora and isn't an error — we count it as 0. An argument could be made that this is degenerate input and we should reject it. I chose to be lenient here because it's a very minor edge case and making it a fatal error felt excessive.
These are all real limitations. I'm flagging them because the thing I don't want you to come away with is "haiku-score is a complete mora solution" — it isn't. It is a correct implementation of the core rules for clean kana input, and a starting point for anyone writing a more sophisticated tool on top. If your application is "check that a haiku a beginner wrote is 5-7-5", it's perfect. If your application is "annotate classical verse with prosodic metadata", you want a different thing.
Try it in 30 seconds
# Build it.
git clone https://github.com/sen-ltd/haiku-score
cd haiku-score
docker build -t haiku-score .
# Basho's 古池 haiku (in kana form — the tool doesn't do kanji).
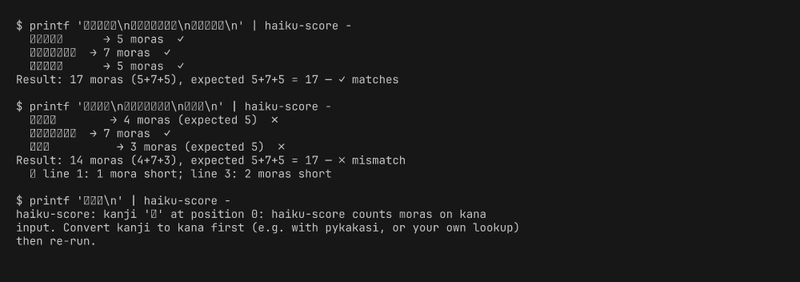
printf 'ふるいけや\nかわずとびこむ\nみずのおと\n' | docker run --rm -i haiku-score -
# ふるいけや → 5 moras ✓
# かわずとびこむ → 7 moras ✓
# みずのおと → 5 moras ✓
# Result: 17 moras (5+7+5), expected 5+7+5 = 17 — ✓ matches
# Try a broken one and watch it explain what's wrong.
printf 'あいうえ\nかきくけこさし\nあいう\n' | docker run --rm -i haiku-score -
# Result: 14 moras (4+7+3), expected 5+7+5 = 17 — ✗ mismatch
# ↳ line 1: 1 mora short; line 3: 2 moras short
# Pass a kanji and see the deliberate non-support.
printf '古池や\n' | docker run --rm -i haiku-score -
# haiku-score: kanji '古' at position 0: ... Convert kanji to kana first ...
# Tanka mode.
printf 'あいうえお\nかきくけこさし\nたちつてと\nなにぬねのはひ\nまみむめもやゆ\n' \
| docker run --rm -i haiku-score - --tanka
# JSON for pipelines.
printf 'ふるいけや\nかわずとびこむ\nみずのおと\n' \
| docker run --rm -i haiku-score - --format json
Takeaway
The thing I keep coming back to with this project is that "counting moras correctly" is a lens that makes Japanese phonology visible in a way textbooks don't. Once you have written code that decides whether きゃ is 1 mora or 2, you can never unsee the difference between き・ゃ and き・よ when you read Japanese. Once you have added a branch for the long mark ー, you notice it every time you see コーヒー. The exercise of making a machine get this right pushes the rules from "facts I memorized" to "patterns I feel", and the fifty lines of Python that do it are a better phonology tutor than any textbook chapter I have read.
If you're learning Japanese, or if you just want to write haiku that actually scans, grab the repo and try your drafts through it. And if you disagree with the kana-only scope decision — the thing I chose to leave out is exactly as important as the thing I chose to keep in — I'd be genuinely interested in hearing the case for integrating kanji conversion. My current answer is "unix pipes and separate tools", but I hold that opinion loosely.


Top comments (0)