
Building a Hash Identifier Without ML — Just Rules, Scores, and Honesty About Ambiguity
Paste a mystery hash, get back candidate algorithms with confidence scores. A zero-dependency Python CLI that covers 15+ formats using a declarative rule table and a scoring function that admits when it doesn't know.
📦 GitHub: https://github.com/sen-ltd/hashid
The problem
You're halfway through a CTF challenge, or you're cleaning up a legacy database, or you're auditing a container image someone handed you, and you see it: a 32-character hex blob sitting in a config file.
Is it MD5? NTLM? A truncated SHA-256? A random token that happens to be hex? A CRC-32 of something, then padded? Without context, the honest answer is "probably one of several things," but the tool you reach for — the classic hashid — returns a flat list of candidates with no ranking, no confidence, no admission of the ambiguity. You get "MD5, NTLM, LM, MD4, RAdmin v2.x, ..." and no way to tell which one to try first.
The classic hashid was last released in 2015. It hasn't seen real maintenance in years, it has no hashcat mode in its output, and — most annoyingly to me — it doesn't score its guesses. When MD5 and NTLM share the same 32-hex shape, returning both with equal weight is technically correct and operationally useless. In my experience, MD5 is orders of magnitude more common in web-app contexts; NTLM is what you see when the hash came out of a Windows SAM dump. A good tool should surface MD5 first and mention NTLM as a plausible alternative, not dump both without comment.
So I rewrote it. Here's what I wanted:
- Rules as data. Adding a new format should be a three-line change, not a refactor.
- Confidence scores. Honest about uncertainty, explicit about collisions.
-
Scriptable output. JSON and CSV formats so I can pipe results into
jqand hashcat. - Hashcat mode numbers on every candidate that has one. This is the #1 thing the 2015 tool is missing.
- Zero dependencies. Stdlib only. I want to be able to drop this into any Alpine container and have it just work.
The whole thing fits in about 400 lines of Python, covers 15+ formats, has 96 tests, and ships as a 60 MB Docker image.
Rules as data
The core idea is that every format detector is a pure function: it takes a string and returns either a Candidate or None. Every rule is identical in shape, so the classifier doesn't need to know anything about any specific format — it just runs all the rules and ranks the non-None results.
A Candidate is a frozen dataclass:
@dataclass(frozen=True)
class Candidate:
name: str
score: float
producer: str
hashcat_mode: int | None = None
john_format: str | None = None
notes: str = ""
@property
def crackable(self) -> bool:
return self.hashcat_mode is not None
Each rule is a function with type (str) -> Candidate | None. The rule table is just a tuple:
RULES: tuple[Rule, ...] = (
Rule("bcrypt", "bcrypt $2[abxy]$<cost>$...", bcrypt_rule),
Rule("argon2", "Argon2 $argon2[id|i|d]$...", argon2_rule),
Rule("md5", "MD5 (32 hex)", md5_rule),
Rule("ntlm", "NTLM (32 hex)", ntlm_rule),
...
)
Adding a new format is: (1) write the rule function, (2) add it to RULES, (3) add a positive and negative test. Nothing else in the codebase needs to change. The classifier, the CLI, the formatters — none of them know about specific formats.
One rule in detail: bcrypt
Most rules are boring: check length, check character class, return a candidate. Bcrypt is the interesting one because the format carries both the variant tag and the cost factor inline, and parsing the cost is useful metadata to surface.
_BCRYPT_RE = re.compile(
r"^\$2[abxy]\$(\d{2})\$([./A-Za-z0-9]{22})([./A-Za-z0-9]{31})$"
)
def bcrypt_rule(value: str) -> Candidate | None:
match = _BCRYPT_RE.match(value)
if not match:
return None
cost = int(match.group(1))
score = 1.00
notes = f"variant={value[1:3]}, cost={cost}"
if cost < 4 or cost > 31:
score = 0.80
notes += " (cost out of normal 4..31 range)"
return Candidate(
name="bcrypt",
score=score,
producer="OpenBSD bcrypt, Python passlib, Node bcrypt, PHP password_hash",
hashcat_mode=3200,
john_format="bcrypt",
notes=notes,
)
A few things to notice. The regex is strict: exactly two digits for cost, exactly 22 characters of salt, exactly 31 characters of hash, all in [./A-Za-z0-9]. A hash that mostly matches but has one character off will return None and the user will see "no candidates" rather than a misleading "bcrypt-ish" result.
The score is 1.00 for canonical-looking bcrypts and 0.80 for ones with an out-of-range cost factor. I could have rejected out-of-range costs entirely, but the job of this tool is to help you identify a hash, not to validate it. If someone stored bcrypts with cost=03, I'd rather tell them "this is bcrypt with an unusual cost" than "this is not a hash."
The notes field gives the user the parsed metadata for free — variant (2a, 2b, 2x, 2y) and cost. You can get the same info by reading the hash yourself, but having it pre-parsed is what separates a usable tool from a toy.
The scoring loop
Here's the whole classifier:
def classify(value: str, *, only=None, crackable_only=False) -> Analysis:
stripped = value.strip()
candidates = [rule.apply(stripped) for rule in RULES]
candidates = [c for c in candidates if c is not None]
if only:
needle = only.lower()
candidates = [c for c in candidates if needle in c.name.lower()]
if crackable_only:
candidates = [c for c in candidates if c.crackable]
candidates.sort(key=lambda c: (-c.score, c.name))
return Analysis(
value=stripped,
length=len(stripped),
is_hex=is_hex(stripped) if stripped else False,
is_base64=is_base64(stripped) if stripped else False,
candidates=tuple(candidates),
)
That's the engine. Every rule runs; the ones that don't match return None; everything else sorts by score descending. --only is a post-filter that lets the user pin the interpretation when they already know the producer. --crackable drops candidates that have no known hashcat mode — useful when the goal is "I want to feed this into hashcat, tell me what mode number to use."
The unavoidable ambiguity: MD5 vs NTLM
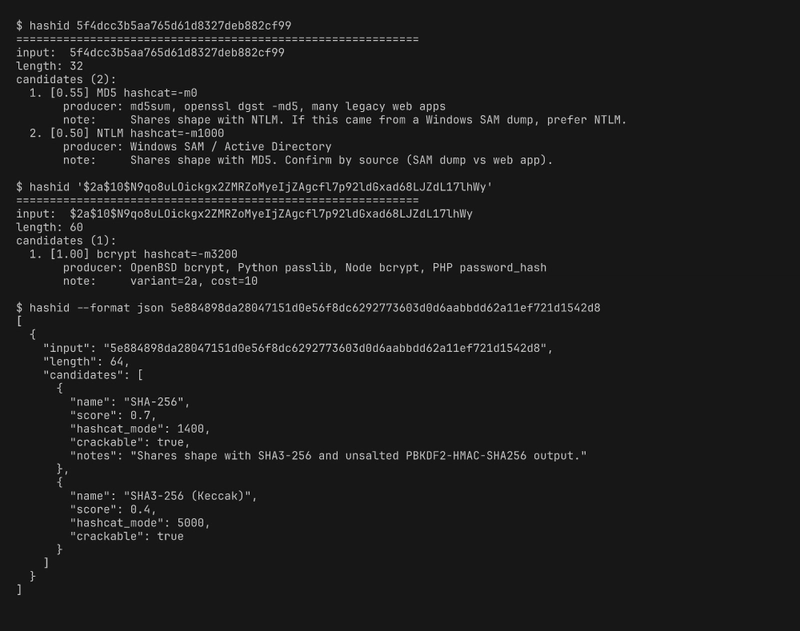
Here's what this tool will tell you about 5f4dcc3b5aa765d61d8327deb882cf99 (which is md5("password")):
candidates (2):
1. [0.55] MD5 hashcat=-m0
producer: md5sum, openssl dgst -md5, many legacy web apps
note: Shares shape with NTLM. If this came from a Windows SAM dump, prefer NTLM.
2. [0.50] NTLM hashcat=-m1000
producer: Windows SAM / Active Directory
note: Shares shape with MD5. Confirm by source (SAM dump vs web app).
MD5 is ranked first because MD5 is vastly more common in the wild than NTLM, but NTLM is right below it because the shape (32 hex characters) is literally identical. There is no algorithm in the world that can distinguish MD5 from NTLM purely by looking at the hash — they're both 128-bit digests rendered as hex. The classifier has to report both and let the user decide based on out-of-band context (where did this hash come from?).
This is the piece I wish the classic hashid had built in. Its output for that input is a flat list of maybe 20 candidates, all presented as equal possibilities — including things like "Haval-128" and "RAdmin v2.x" that, in 2026, are vanishingly unlikely in practical contexts. The scored version gives you "it's almost certainly MD5, possibly NTLM, we can't tell you more without knowing where it came from." That's a materially more useful answer.
The same pattern happens at several other lengths:
-
40 hex: SHA-1 (score 0.55) vs raw MySQL 5+ (0.45). MySQL 5 is
sha1(sha1(password)), which is structurally a SHA-1. Without the leading*that MySQL normally writes, you can't tell them apart. - 64 hex: SHA-256 (0.70) vs SHA3-256 / Keccak-256 (0.40). SHA3 is much rarer in password-storage contexts but very common in Ethereum-adjacent work, so a user who knows their context might prefer the lower-scored candidate.
- 128 hex: SHA-512 vs SHA3-512. Same story.
The scoring function bakes in a prior about prevalence. When a user knows their prior is different from mine — because they're staring at a SAM dump or an Ethereum transaction — --only NTLM or --only SHA3 pins the interpretation and the classifier returns just that one.
Tradeoffs and honest limits
A few things this tool does not and will not do well:
Rare or regional formats. I cover the big names (bcrypt, argon2, scrypt, the crypt() family, Django PBKDF2, MySQL 3.23 and 4.1+, LDAP {SSHA}, raw hex digests, base64 digests). I do not cover things like Cisco Type 7, Juniper $9$, Oracle DES, WebLogic, RADIUS, or the long tail of vendor-specific formats. Adding them is easy — write a rule, add a test — but each one adds false-positive risk.
Salted vs unsalted inside prefix-tagged formats. When a hash is $6$...$... I know it's sha512crypt, but I can't tell you anything about the password complexity or even whether the hash is well-formed from the inside. The tool tells you the format, not whether the format was used correctly.
Non-hash strings that happen to match. A random 32-character string from [A-Za-z0-9./] has some probability of matching the DES crypt rule. That rule is scored at 0.55 specifically because the match is weak — DES crypt is only 13 characters, which is far too few to be uniquely identifying. A savvy user treats a lone DES crypt candidate with skepticism.
Base64 digest inference. A 44-character base64 string ending in = is a very weak signal. It could be SHA-256, it could be a 32-byte AES key someone base64-encoded, it could be anything. The tool reports it with score 0.40 and a note saying so. Users need to know what it is from context.
Try in 30 seconds
git clone https://github.com/sen-ltd/hashid
cd hashid
docker build -t hashid .
docker run --rm hashid 5f4dcc3b5aa765d61d8327deb882cf99
# → MD5 (0.55), NTLM (0.50)
docker run --rm hashid '$2a$10$N9qo8uLOickgx2ZMRZoMyeIjZAgcfl7p92ldGxad68LJZdL17lhWy'
# → bcrypt (1.00), cost=10
docker run --rm hashid --format json 5e884898da28047151d0e56f8dc6292773603d0d6aabbdd62a11ef721d1542d8
# → SHA-256 + SHA3-256 candidates as JSON
docker run --rm hashid --only NTLM 5f4dcc3b5aa765d61d8327deb882cf99
# → NTLM only (pinned)
docker run --rm hashid --crackable '$6$salt$...'
# → only candidates with known hashcat mode
Pipe a list of hashes:
cat suspicious-dump.txt | docker run --rm -i hashid --stdin --format csv > report.csv
The Docker image is a 60 MB alpine multi-stage build. Everything runs as a non-root user. Zero network access is needed — the classifier is pure stdlib, and there's nothing to phone home to.
The point
Pattern classifiers without learned models are not glamorous, but they're often the right tool when the input space is fully enumerable and the rules are human-auditable. For hash identification specifically, there's nothing to learn that can't be written as a regex over a length and a character class. The interesting design work is not the rules themselves; it's the scoring function that admits when it doesn't know, and the UX that helps the user give the classifier the context it needs to break a tie.
A hash identifier that tells you "it's one of these three, sorted by how likely, here's the hashcat mode for each" is more useful than one that tells you "it's definitely this" — because when your problem is a mystery hash, the right answer is almost always "probably X, possibly Y, and here's how to tell."


Top comments (0)